>>>> * Primary References
>>>> * History of the (seed * 16807 mod(2^31 - 1)) Linear Congruential Generator (LCG)
>>>> History of the Implementation Debate
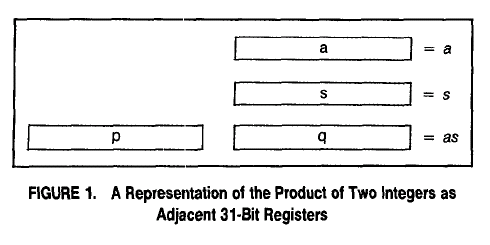
>>>> A Simpler Explanation of David G. Carta's Optimisation
>>>> Implementations using Schrage's and Carta's approaches
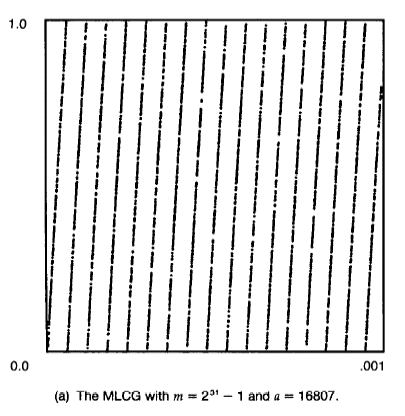
>>>> * Quality of the Pseudo-Random Numbers
>>>> * Source Code
>>>> Improving the Quality of Pseudo-Random Numbers
>>>> Extending the Carta Algorithm Towards 64 bits
>>>> Musings on the Philosophy of Science
>>>> Links
>>>> Update History
C code without comments:

Less than 33 CPU clock cycles (including function call overhead and a loop with an output comparison test) on a Pentium III, with some compiler optimisations. (Less then 28 clock cycles with Andrew Simper's optimisation..)dsPIC code without comments: