If the Internet's
routing system (about
63,000
BGP routers, according to the number of lines in "Lists of
alias clusters" at
iplane.cs.washington.edu/data.html
)
could easily route
packets to any individual IP address, when a computer with
each address is connected to the Internet via any ISP in the
world,
then there would
be no crisis in routing or addressing.
Address space could be used very efficiently, one at a time
for
each computer, and computers or complete networks could freely move,
keeping their addresses, no matter which ISP they used. There
are
about
3.7
billion IPv4 addresses available and since there
aren't that many computers in the world (yet) there would be no
shortage of address space (yet).
There is a
shortage of IPv4 address space
now, because the Internet's routing and addressing architecture is
rather
clunky
about the large minimum size of the lumps of address space which must
be handed out. None of this clunkiness and resultant
inefficient
use of address space - including the constant effort to maximise "
route aggregation" -
would be needed if the routing system behaved as just described.
This address shortage is going to hit a
crunch time about 2010,
despite only about
5%
(or maybe
10%
- nobody really knows)
of
the addresses actually being used. (See my page
../../host-density-per-prefix/
for an attempt to find this out.)
The
Internet's routing and addressing system is facing a crisis.
There needs to be a new architecture, and perhaps the new
architecture will enable fine-grain (single IP
address
granularity) management of some of the address space, with fast (a few
seconds) control of where the packets are sent to, without involving or
upsetting the existing BGP system. This is a bold and
exciting
prospect, in part because it should allow a much more efficient usage
of some or much of the IPv4 address space.
In
reality, routers can't do anything like the "single IP address
granularity" routing I described in the first paragraph. The
IPv4
Internet's BGP (
Border
Gateway Protocol) routing system currently (mid-2007)
copes with about 220,000 divisions of the address space, each known as
a "prefix".
Most of these 63,000 routers
are in the "
Default Free
Zone" (DFZ). These are
transit routers
(simply connecting to other routers) or the
multihomed border routers
of networks run by
ISPs
or what I call "
AS-end-users"
such as universities, corporations etc. (Organisations with an
Autonomous System Number,
their own
Provider
Independent address space,
and one or more BGP routers - who do not sell connectivity to anyone
else.) A multihomed border router is one with two or more
upstream connections to "the rest of the Internet". These
routers
need to make their own decision about which of their peer routers (two
or more other routers, perhaps dozens of them, which the router has
direct links to) packets should be forwarded to, depending on the
destination address of the packet. Each router needs to
figure
this out for itself, since it is in a different part of the network
topology than every other router. Each router needs to figure
out
a rule for which peer to forward packets to, with a separate rule for
each of the 220,000 (and growing rapidly . . .) prefixes which
the
address space is divided into.
Border
routers which are
not multihomed - meaning they are "singlehomed", having a single
upstream link to "the rest of the Internet" - don't need to develop a
rule for how to route packets for each of these 220,000+ prefixes.
This is because the router needs to know only about whatever
small subset of these prefixes are within its own network, and then any
packet which doesn't match one of those is simply forwarded out the
interface for the single upstream link. This is the "default
route", which transit routers and multihomed border routers don't have.
Finding
the best protocol by which the DFZ routers compare notes so
each
can figure out how best to route packets addressed to each of the
220,000+ prefixes turns out to be
a
very difficult engineering problem. The current
solution (it has been
the
solution since the late 1980s) - BGP - involves highly simplified
messages being exchanged between peer routers. The messages
are
intentionally simplified so the router can cope with a large number of
them. This is so the routing system can scale to a large
number
of prefixes, such as the 220,000 prefixes of mid-2007. This
is rowing alarmingly at about 20% per annum:.
bgp.potaroo.net .
These
messages don't describe everything about the location of
the border router to which packets should be sent when their
destination matches the particular prefix. They messages
mainly
concern one peer router saying "I can get packets addressed to prefix X
to their destination by
a
path which involves traversing 5 Autonomous Systems.
Here is a list of the ASNs of those systems." - and another
peer
router saying the something similar, regarding the same prefix, with
perhaps a different number of Autonomous Systems, and perhaps a
different list of
AS
numbers.
Each
router looks at these messages from its peers, for any given prefix,
and (depending on generally simple but sometimes complex
criteria) chooses to send the packets to the peer which has
the
path which traverses the least number of Autonomous Systems.
Note
this "path length" number is not the number of routers - there may be
one or a dozen routers in the path all belonging to an AS, such as that
of a transit provider or an ISP. So this method of choosing
the
best path is very approximate. The path length
doesn't say
anything about how fast these routers are, how fast the data links
are, how busy they are, or about the distance between
the
routers.
Each BGP router has this sort of "comparing
of notes"
conversation with each of its peers, about each of the 220,000
prefixes. For each of these conversations (for instance with
15
peers, 3.3 million two-way conversations), the router stores "state"
(information in RAM) such as the latest "best path" the peer told it.
Whenever a router decides on a new best-path for a prefix -
which
it does according to policy rules set by the organisation who runs it
and according to the current "best paths" from its peers - it tells its
peers (actually, not necessarily all of them) its new "best-path".
(When
a router boots up, it has no storage of routing information from when
it last ran, so it asks all its peers to tell it all their best paths.
From this it determines its 220,000 best paths, and then
tells
these to all its peers. After this, the peers only tell each
other something if there is a change to one of their "best paths".
The message system between each peer is rock-solid TCP, not
based
on unreliable UDP packets.)
So when one of the
220,000+ prefixes
is disconnected from the Net, news of this propagates through the BGP
network, all around the world, by one router telling its peer that
either it has no path for a given prefix, or that its previous best
path is no longer valid, in which case it gives a new best path, which
may well traverse more Autonomous Systems. This may change
the
next router's "best path" decision, in which case it announces its
decision to all its peers.
There are many troubles
with this.
The changes can propagate rather slowly - at best it takes a
few
minutes to propagate across the Net. Sometimes, it can take much
longer. During this "convergence" time, packets may be
delivered
by longer than optimal paths, which is not such a problem. A
worse problem is that they may be sent along paths which don't work.
So the packets are dropped ("black-holed") while in fact
there
was a path by which they could have been successfully delivered.
These
peer-to-peer BGP conversations involves the router's CPUs in a
lot
of complex work. The routers have timers to try to suppress
spurious activity, but these can lead to the changes propagating very
slowly, or to some false changes propagating (such as a new, longer,
"best path" when in fact there is no path at all) until the timer times
out. The messages are so simplified that a router can't tell
from
one path being withdrawn whether another similar looking path will work
or not.
This is a brief account of a long story.
It took
me a long time to understand that
the BGP system is the real problem in
the Internet's routing and addressing system today.
At
first, I
thought we could just soup up the Forwarding Information Base (FIB)
aspect of routers - the part which handles the incoming packets and
magically compares each packet's destination addresses with 220,000+
rules, in less than a microsecond, in order to decide which interface
to forward it to. There are some great improvements to be
made in
the FIB, for instance to make them handle millions of prefixes, such as
all 14.5 million 256 address "/24" prefixes in the whole
address
space. (That would not be as good as the ideal "flat
routing" each of the 3.7 billion individual IP addresses, but it would
be a great improvement on the current messy arrangement.)
However
there is no point in souping up the FIB for 14.5 million separately
routed prefixes as long as the RIB (Routing Information Base) and the
BGP aspect of the routers is struggling with 220,000 prefixes today.
It
turns out that BGP is hard to improve upon.
There
are some marginal improvements to be made, for sure, but those will
take a few years and will only provide small increments in performance,
equivalent probably to a year or so's growth in this
rapidly growing set of 220,000
prefixes, which is generally known as the
Global IPv4 BGP Routing Table.
Maybe
someone could devise a different global routing protocol, but no-one
seems confident of making one which could respond rapidly, handle
millions of prefixes, and do so within the constraints even the biggest
router's CPUs must live within.
No-one has a
credible plan for seamless transition of the BGP network to something
radically different.
So
we are stuck with BGP. It could be worse - BGP is
a venerable and carefully designed protocol, which is working
quite well now, despite the demands placed upon it being far beyond
what its mid-1980s designers could have anticipated.
(Pause to look out the window . . . )
In
October 2006,
the Internet Architecture Board ran a workshop (the RAWS Routing and Addressing WorkShop) in
Amsterdam about the routing and addressing problems. The RAWS site:
www.iab.org/about/workshops/routingandaddressing/ and report:
tools.ietf.org/html/draft-iab-raws-report are essential reading.
Most of
the
discussion concerned IPv4, but
IPv6
will run into the same troubles with BGP if and when it is widely
adopted. In mid-2007, the IPv6 global BGP routing table has
less
than a thousand entries. See Gert Doering's (Gert
Döring's)
latest report at
www.space.net/~gert/RIPE/
.
IPv6 has a vast address space, since it uses
128 bit addresses,
instead of IPv4's 32 bits. While there is never likely to be
a
shortage of IPv6 address space, these longer addresses are generally a
pain for all concerned, especially the FIB section of routers which
need to classify them according to up to 48 bits, whereas with IPv4
packets, usually no more than 24 bits need be analysed.
Changing
over to IPv6 is not really an option (despite what its proponents say)
for most users, since it involves a bunch of problems, involving complications using their
applications, operating systems which are not all that well
tested
with IPv6 and/or application software which would ideally be rewritten
to take full advantage of dual-stack connectivity to both the IPv4 and
the IPv6 Internet.
So we can't
all move to IPv6. If we did, the same BGP problems would
arise, and the FIB troubles would be worse.
We can't
replace or seriously upgrade BGP.
We
can't expect everyone, or really anyone, to change the operating system
software or the application software of their desktop computers or
servers which handle the packets somewhat like routers, but don't need
hardware FIBs or multiple interfaces like mainstream routers.
This means the changes must occur in the
existing routers, or perhaps with the addition of new routers and
servers.
We can't make changes which involve some
computers not being able to send packets to other computers.
The
new solution needs to work much the same for both IPv4 and IPv6.
It
needs to involve the smallest number of changes possible.
Ideally, most existing routers will continue to operate
without
any changes.
The new system must be
Incrementally Deployable.
This means it must, at least:
Provide immediate
advantages (benefits more than costs) to whoever starts to use the
addresses governed by the new system.
It
must provide some reasonably immediate benefits to whoever builds the
new infrastructure, installs new or upgraded routers etc. which makes
the new system work.
We have to invent a new
routing and addressing architecture for the Internet . . . soon.
I
don't think this can be achieved before 2010, which is when the fresh
supplies of IPv4 address space are expected to run out. I
think
that some of this space should be set aside for the new architectural
solution, rather than making that solution have to work purely from a
mish-mash of address blocks.
(Now for some solutions . . . )
There has been a
long history of "
Locator
- Identifier" separation proposals. Very
loosely, this is like saying:
"I
want a postal address people can always send mail to me on, but I want
it to work wherever I move to, so I don't have to tell anyone I have
moved. So there must be two classes of postal address: one
(ID)
which identifies me, and is used by people who send me letters and
another (Loc) which changes as I move house. There also needs
to
be a central database so every Post Office sorting house can look up my
ID address and find my current Loc
address, which is the address of the Post Office delivery office which
actually delivers letters to my letterbox. Then the sorting
office will put the letter in an
envelope addressed to that Loc address. When this envelope
arrives at the delivery office near where I live, the people there
take the inner
envelope
out from the outer envelope, and the delivery person
("Postie" in
Australia) then knows how to get the original envelope to my
letter box."
Some
of these proposals involve major conceptual changes to the TCP/IP
protocols, for instance with completely separate types of addresses for
ID and Loc. These will never be implemented, since they
require
changes to everyone's operating system and application programs.
Perhaps
the first proposal which doesn't involve such changes to end-user
computers' operating systems or application programs - and which is
intended to work for both IPv4 and IPv6 - is
LISP - the Locator/ID Separation
Protocol.
The initial LISP Internet
Draft (I-D) was written in early 2007. It has been widely
discussed on the
RAM list
(Routing and Addressing Mailing list, which grew out of the IAB
Amsterdam RAWS workshop). LISP has multiple variants.
LISP
1 and 1.5 are not intended to be practical solutions to the
routing and addressing problems, but are theoretical models for
exploring the variants which are intended to be practical.
These
are LISP 2.x and LISP 3.x. I won't go into too much detail,
except to say that by June 2007, there were two LISP 3.x proposals with
I-Ds:
LISP-NERD
and
LISP-CONS.
LISP
proposes there be a bunch of
Ingress
Tunnel Routers (
ITRs),
which intercept packets addressed to the "ID" addresses, and places
them into an envelope (encapsulates them into a UDP packet) which
is addressed to to the
Egress
Tunnel Router (
ETR)
which knows how to pop the packet out of the envelope, and deliver it
directly to the destination computer, or to the destination
router in the case where a whole prefix of addresses is being "mapped"
to a particular location.
LISP, like the other proposals discussed below requires
some kind of
ID to Loc
mapping database and a method of the ITRs finding out the mapping information they need from this database.
Unfortunately, the
extra encapsulating header
of each tunneled packet is likely to cause problems with
whole packet being too long for one or more routers or data
links
on the path to the ETR. This will cause lost packets (ideally not) or ugly, inefficient,
fragmentation into smaller packets en-route (for IPv4). IPv6
doesn't fragment packets en-route, so there will need to be some
solution which we don't know yet. This turns out to be a
messy
problem for LISP and the other proposals discussed below.
There
will be a solution, but I suspect it will involve all, or at least
most, computers in the Net generally sending packets with a slightly
shorter maximum length. This would result in an overall slight loss of
efficiency, including for many packets not using the new
LISP-etc.-mapped addresses, but at present I see no
alternative.
There is another proposal called
eFIT-APT.
Perhaps the APT part could be applied to LISP.
NERD,
CONS and APT are basically methods of having a centralised (and/or
distributed) database of mapping information tell the ITRs how to do
their job. The ITR's job is closely analogous to that of
the Post Office sorting offices' job: intercepting mail which
is
addressed to my "ID" address, putting each letter into an
envelope
and mailing it to a delivery office which is currently, ideally, the best way to get packets to the destination.
Unlike
some other proposals, the ID and the Loc addresses are both ordinary IP
addresses.
In
mid June I was thinking about what I considered a major problem with
LISP 3.x (meaning LISP-NERD, LISP-CONS or any similar thing).
The
way LISP was (and in mid-July 2007, still is, formally) defined,
computers in networks (ISP and AS-end-user networks) which have not
been upgraded to LISP would not be able to send packets to computers
whose addresses are part of the new LISP-mapped addressing system.
Some other people also considered that this
prevented LISP
from being
Incrementally
Deployable.
I though of a variation on
LISP to solve this problem of "unreachability from non-upgraded networks". This variation can be tersely described as "
anycast ITRs in the core".
It seems no-one had thought of this before.
Anycast
is an unusual arrangement, normally only used in the Internet for the
Root Nameservers, where a single prefix of IP addresses is "advertised"
by multiple BGP routers in widely different locations.
Normally a
prefix is announced by only one border router. With anycast,
there is no absolute stability in which router a packet will be
delivered to. For instance if there were anycast routers for
the
prefix 20.0.0.0/24 in Boston and Washington DC, a packet addressed to
20.0.0.3 sent from New York might sometimes go to the Boston router and
other times might go to the DC router. The exact path depends
on
how the various BGP routers compare notes and decide their "best path"
to this prefix.
This lack of certainty about which
router the
packet will go to means that anycast is normally only used for
simple communications involving a single query and a single reply
packet. An attempt to build a long-lasting multi-packet
session
would probably not work reliably, since at any time, due to a slight
change in the way BGP routers make their decisions, the packets from
New York might go to the 20.0.0.3 server in DC when the session was
originally established with the 20.0.0.3 server in Boston.
But
anycast should work fine for ordinary Internet session-based
communication (such as TCP, HTTP, SMTP for email etc.) with
anycast ITRs, since each ITR is the input of a pipe, where all
the
outputs of the multiple ITR's pipes go to the one ETR, and the packets
always arrive at the one destination computer, which is actually
responding to the packets and conducting the communications session.
I
called my proposal "Ivip", inspired by Rock Hudson's "Vip" in the 1961
romp with Doris Day and Tony Randall: "Lover Come Back".
I
wrote up my thoughts on the RAM list in a series of brainstorming-style
messages.
Several
people liked the idea, but the mailing lest messages were very hard to follow.
By
mid July 2007, I had version 00 of the Ivip-architecture I-D.
It
is long, but it covers a lot of ground and it is hopefully easy to read
without too much head-scratching.
In the week before
the late
July IETF-69 meeting in Chicago, I wrote on the RAM list a comparison
../comp/ of LISP-NERD, LISP-CONS, eFIT-APT and Ivip. After feedback
from
the developers of these proposals, my site has an updated
web-page version of this comparison, with links to the I-Ds of
these proposals.
In the week of the IETF-69 meeting,
I also
wrote a set of "slides" (a Power Point presentation, in tables and
text, with no extraneous stuff whatsoever - and also available as a
PDF) comparing the proposals in different ways than the web page, and
discussing some challenges I think all these proposals face.
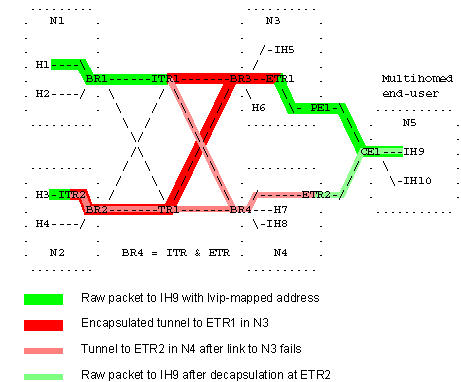
Then
I wrote this page, and a colour diagram of multihoming service
restoration, which I added to the slides. This page and the
diagram will hopefully make it easier for people who are new to the
field to understand what I call the "crisis" and to understand a little
about the current proposals for resolving it..
Here are some contrasts between Ivip and the other proposals.
LISP-NERD,
LISP-CONS and eFIT-APT all assume that it is going to be difficult and
slow to have a "ID-Loc mapping database" control the tunneling behavior
of a worldwide set of (tens or hundreds of thousands of) ITRs.
This is not an unreasonable basis to work from, since it is
certainly difficult to imagine how to get the changed mapping
information (postal equivalent: when I move house, my ID address and
the new delivery office nearest my new house) to every ITR within a few
seconds.
Consequently,
these proposals require the ITRs
to make a bunch of short-term decisions
themselves. In these proposals, it is the ITRs which must
decide
whether to tunnel packets to one ETR or another, when the destination
host or router uses
two
ETRs in two separate ISP networks to provide robust, multihomed, links
to the Net.
The one big thing that all
these proposals must do is
enable end-users to multihome their networks
(and, ideally, individual computers) without getting an AS number, and
most importantly without needing to get their own Provider Independent
address space (minimum chunk size 256 even if they only want one or a
few addresses) and adding one more route to the
Global BGP Routing Table
when this address space is advertised on BGP by whichever of their two
ISPs they are currently using.
The
number one goal of all these proposals, is to limit or reduce the
growth in the Global BGP Routing Table by providing a non-BGP approach
to multihoming for the potentially millions of end-users who want and
need multihoming and/or address portability when they change ISPs.LISP-NERD, LISP-CONS
and eFIT-APT all have a
complex
database
giving the ITRs various options for different ETRs to use when another
ETR is not reachable. These proposals involve the ITRs and
ETRs
in
complex communications,
in part to establish which ETR is
reachable.
These complex communications present many
security vulnerabilities,
and involve the ITRs' and ETRs' CPUs in a great deal of work.
Ivip
differs very much from these three proposals.
In
addition to the "anycast ITRs in the core" idea, Ivip does not involve
the ITRs or ETRs in any communications between themselves.
Ivip
ITRs simply tunnel packets to a single ETR (location) address, for each
original destination (ID) address. The ITR makes no decisions
and
does not test to see if the ETR is really reachable. This
makes
Ivip's database
structure much simpler and more compact. It also
removes many of the security vulnerabilities which the other proposals
are subject to.
Ivip
relies on some external system, as chosen by the end-user whose
computers use the Ivip-mapped addresses, to control the mapping
database for their addresses. This means that for multihoming
service restoration, the Ivip system is just a component of a solution
which the end-user can create themselves. With the other
proposals, the whole multihoming and traffic engineering solution must
be built into the one monolithic system.
The only
way Ivip makes sense is if there is a
really fast (one
to five seconds, ideally one or two seconds) system by which a user can
change the mapping of their address (change which ETR the packets will
be tunneled to) and have this change followed by all ITRs the world
over in this short time.
This involves
an ambitious Replicator system.
This is the most challenging part of Ivip.
I
reckon it can be done - but it is early days yet.
This paragraph was the subject of a second critique:So
in summary, the other proposals say: "We can't get the database updates
to the ITRs quick enough that the end-users (or their chosen
multihoming monitoring systems) can restore service quickly enough
simply by changing the mapping, so we must make the ITRs figure out the
service restoration themselves . . . in which case we need a more
complex database."