Lossless
Compression of Audio
This page comparing various lossless audio compression algorithms
and
programs hasn't changed much since January 2003. I am no longer
maintaining it and I suggest that the best place to maintain an
up-to-date account of this subject is in the Wikipedia at:
http://en.wikipedia.org/wiki/Audio_data_compression#Lossless_compression
Some short updates
If you want the test samples . . .
Update 2010-04-16:
I apologise for the test files not
being available for some time. I have not been able to find my
December 2000 CDRs of these files. This was the basis of what I
used to have in a separate directory, which I described in this way:
I have a set of audio samples which I think give a good
range of material to try compression algorithms on. I can send
this to you on two CD-Rs if you like, or if you have broadband Internet
and are happy to download a bunch of stuff (674 Megabytes) you can get
Zipped (ordinary Zip format) compressed versions of the 11 music tracks
I used for these tests. Please see
../../0-big/
and give the username
lossless
and the password
audio. There is also a bunch of
compression programs there and the batch files etc. I used for
testing. The files on these CD-Rs, and in the above-mentioned
directory, are from December 2000.
I have found most of the test files - 00 HI to 10SI - and these are avialable: Please see
../../0-big/
and give the username
lossless
and the password
audio.
The test files are stereo 44.1kHz 16 bit .WAV files, compressed with
PKZIP - so they can be decompressed by WinZip and many other
programs. The Unix/Linux "unzip" program can also decompress them.
Why I am no longer pursuing this field
The question of compressing audio without any loss of
quality (including especially without having to even think about how
lossy a lossy algorithm is, because the binary bits are fully restored)
is obviously important. I partially developed my own algorithm
and found it was not as good, at least initially, as existing
approaches.
I have a very strong sense - and I think it is shared by many people
with experience in this field - that existing algorithms come within a
few percent of theoretical limits in terms of compression
efficiency. No-one knows exactly the maximum compression which
could be achieved on a given file, but the way the various algorithms
all approach a particular percentage for a particular piece of music,
and how those percentages vary widely according to the nature of the
music, seems to indicate the best of the algorithms is getting close to
some unknown theoretical limit.
Therefore, in my view, straight-out improvements in compression ratio
are likely to be limited to a few percent. Since the cost
of storage is falling precipitously (RAM, hard disks, FLASH memory,
writeable DVDs etc.) and since the costs of transmission (Internet in
general and broadband access to the Net in particular) are falling
while transmission speeds are generally improving, I don't feel like
doing a lot of work to achieve minor improvements in file size. However,
I salute those who are pursuing this!
There are improvements to be made beyond compression ratio:
- The
efficiency (CPU cycles required) of the compression
algorithm. In most cases, apart from portable audio recorders, I
don't think this matters as much as efficiency of decompression.
- Efficiency of decompression. On a modern PC, most of
these algorithms are going to place very modest demands on the
CPU. Decompression efficiency is more important for hand-held
devices with smaller, slower, CPUs and restricted battery life.
- Portability - the code being written in C or C++ in an
elegant,
modular and very well commented fashion.
- Copyright
of the code - open-source software.
- Ultimately,
by hook or by crook, one or perhaps a few
algorithms gaining sufficient support to be effectively, or formally,
standardised and therefore very widely used.
- Ease
of use of the software.
Before I sign off, here is a mini rant
about sampling
rate and bit-depth for audio recording.
When recording raw audio, I think its good to use a 20 bit converter
and run at a higher than normal (44.1kHz) sampling rate if
possible. This makes it easier to avoid clipping with unexpected
high peaks.
With the following exceptions, I think that for mixed, finished, music,
there is no point in going beyond 44.1kHz 16 bit stereo:
- If
you want to reproduce frequencies you can't hear (on their
own) for the purposes of multiple such tones distorting and therefore
inter-modulating in your ear so you can hear the differences between
their frequencies (which do fall within audible frequency limits) then
by all means use higher sampling rates.
- If you
want to be able to reproduce sound levels which are
painful or damaging, whilst preserving a signal-to-noise level which
makes noise and distortion inaudible when you place your ear right up
to the speaker, then by all means use more than 16 bits.
- If you want to feel superior to people using lesser bit depths
and sampling rates - or want to make potential customers feel
inadequate unless they buy your product and run at your exalted bit
depths and sample rates - then by all means denigrate 44.1kHz 16 bit
and make quasi-religious claims about fancier schemes. (These work a
treat with the "if I don't understand it, it must be profound" crowd.)
When thinking about edited, ready-to-listen-to, audio, as far as I
know, in any realistic listening situation, with proper care and the
best techniques, there is no audible degradation in using 16 bit
44.1kHz stereo. By this I mean that if the physical sound level
is such that the highest peaks won't cause serious discomfort, then you
won't be able to hear the noise and distortion which is inherent in
properly done 16 bit audio. There should be no distortion -
because the dither should linearise it and the result becomes part of
the 1 step noise floor. With care, it is not hard to get the
frequency response flat from 30 Hz to 18 kHz, and for there to be no
"phase distortion" - no shifting of signals according to their
frequency. So all that is left is the dither and the way the
dither interacts with the signals to linearise them, perceptibly
several bits below the limits of a 16 bit system without dither.
Many people attest that they can hear the difference between 16 bit
44.1kHz audio and some higher sampling rate and/or bit depth. My
response to this is that they are not necessarily listening to 16 bit
44.1kHz done properly - or alternatively that the difference they hear
is actually that the other format does change the sound.
The only real test is to switch between a live (analogue microphone)
signal and its digitised and regenerated version.
Most physical audio situations (rooms, outdoors etc. with a microphone)
have a signal-to-noise ratio well below the ~96db inherent in a
properly engineered 16 bit system. Good Delta-Sigma ADCs, as far
as I know, are capable of remarkably good conversion of any waveform
(apart perhaps from rail-to-rail square-waves and the like), and
properly constructed oversampling DACs can work fine too. These
can both work without any significant distortion, noise or phase
problems.
Audio recorded at 96kHz with a 24 bit sample rate will be very hard to
compress losslessly. Firstly, the sampling rate is over twice
what I think it really needs to be. Secondly, of the 24 bits,
only 14 to 16 are going to be of a musical signal and the rest will be
random noise from:
- Noise in the environment picked up by
the microphone.
- Brownian motion (random impact of
air molecules) on the
microphone diaphragm - which is reduced in proportion to the signal
with a larger microphone.
- Electrical noise in the
microphone amplifier and subsequent
stages before the ADC. (Brownian motion is usually much higher then the
electrical noise.)
- Noise from the ADC. Just
because an ADC puts out 20 or 24
bits doesn't mean that they are all signal. I think that even if
you clamp the input to ground, the bits beyond 16, 17 or 18 will be
random noise in most cases.
Below this, apart from a few fixes to typos and other things (which
were important - thanks!) the page is basically as it was in January
2003.
- Tests of Shorten, MUSICompress/WaveZIP
, WaveArc, Pegasus SPS (ELS-Ultra), Sonarc, LPAC
, WavPack, AudioZip, Monkey and RKAU
audio
compression software.
- Links to material
concerning the lossless
compression
(data reduction) of digital audio signals, including some other
programs
which I did not test.
- A detailed look at Rice
coding and other
techniques
for compressing integers of varying lengths - particularly Elias coding
and
the work of Peter Fenwick.
My particular interest is in delivery of music via the Net - with
compression
which does not affect the sound quality at all. I am
primarily
interested in compression ratios, not speed of the programs. This
is
the first web site devoted to listing all known lossless audio
compression
algorithms and software - please email your suggestions and I will try
to
keep it up-to-date.
Copyright Robin Whittle 1998 - 2000 rw@firstpr.com.au
Originally
written 8 December 1998. Complete new test series and update 24
November to
11 December 2000.
Latest update 13 January 2003. The update history is
at the
bottom of this page.
Back to the First Principles main page
-
for material on telecommunications, music
marketing
via Internet delivery, the Devil Fish TB-303 modification, the
world's
longest Sliiiiiiinky and many and other show-and-tell items. To
the /audiocomp/ directory, which leads to
material
on lossy audio compression, in particular, comparing AAC, MP3 and
TwinVQ.
| This new series of tests was performed as a
project
paid for by the Centre for Signal Processing, Nanyang Technological
University,
Singapore. Dr Lin Xiao, of the Centre, whose program AudioZip
is one of the ten programs I tested, was keen that my tests be
independent.
To this end, I used exactly the same test tracks I used in 1998, adding
only
two pink noise tracks which do not count towards the averages for
file-size
and compression ratio . Thanks to Lin Xiao and his colleagues for
enabling
me to do a proper job of this! Let me know if you would like me to
send you a dual CD-R set
with
all the test files so you can reproduce these tests yourself. |
Tests: what can
be
achieved with lossless compression?
Short answer: 60 to 70% of original file-size with pop,
rock,
techno and other loud, noisy music; 35% to 60% for quieter choral and
orchestral
pieces. My primary interest is in compression of 16 bit 44.1
kHz stereo
audio
files - as used in CDs. There are lossless compression systems
for
24 bit and surround-sound systems. While I have a few links to
these,
they are not tested here. My tests are for programs which
run
on a Windows machine, though I have Linux machines as well, and some of
these
programs run under Linux too. I only found one Mac-only
lossless
compressor (ZAP) and have not tested it.
In my 1998 tests
I was not interested in speed, but in
November
2000, in view of the fact that the compression ratios of the leading
programs
were fairly similar, I decided to test their speed as well, since this
varies
enormously.
Five programs distinguished themselves with high
compression
ratios:
- Dennis Lee's Waveform Archiver (WavArc).
- Tilman Liebchen's LPAC.
- Lin
Xiao's AudioZip.
- Matthew T. Ashland's Monkeys
Audio.
- Malcolm Taylor's RKAU.
Since
each program performed differently on different types of
music,
and since the choice of music in these tests is arbitrary, I cannot say
with
confidence that any of these programs will produce generally higher
rates
of compression than the others. With my particular test
material,
all five produce significantly higher rates of compression than the
other
programs I tested. Since the difference between the best three
programs and the next
best
three is only a few percent, many other factors are likely to influence
your
choice of which program is most useful to you.
A full
description of the test tracks follows the test results
themselves.
All tracks were 44.1 kHz 16 bit stereo .WAV files read directly from
audio
CD and are either electronic productions or microphone based recordings
-
except for my Spare Luxury piece which was generated entirely
with
software. The music constituted 775 Megabytes of data
-
73 minutes of music. The tabulation of these figures was
done
by MS-DOS directory listings and pasting the file-sizes as a block into
a spreadsheet. (See notes
below on exactly how I did it.) Those files are here: sizes9.txtand lossless-analysis.xls . I am
pretty
confident there are no clerical or other errors, but these intermediate
documents
enable you to check.
Audio files contain a certain amount of
information - "entropy" -
so
they cannot be compressed losslessly to any size smaller than
that.
So it is not realistic to expect an ever-increasing improvement in
lossless
compression algorithm performance. The performance can only
approach
more closely whatever the basic entropy of the file is. No-one
quite
knows what that entropy is of course . . . I think that would require
understanding
the datastream in a way which is exactly in tune with it's true
nature.
For instance a .jpg image of handwriting would appear to contain a lot
of
data, unless you could see and recognise the handwriting and record its
characters
in a suitably compressed format. The true nature of sound varies
with
its source, physical environment and recording method, and a lossless
compression
program cannot adapt itself entirely to the "true" nature of the sound
in
each piece of music. Therefore it is not surprising that
different algorithms
work best on different kinds of music.
Here are the test
results, with the figures in the main body of
the
table showing the compressed file size as a function of the
original
size. Those instances which are the smallest are in bold-face,
larger
characters and with a green background. The average file sizes
are
the average of the file sizes of the test tracks 00 to 10.
The
average compression ratio is simply 100 divided by the average file
size
percentage. Except where noted (WaveArc -4 and with RKAU -l2 and -l3) I
have
selected the highest compression option for all programs tested.
The
two test files 11PS and 12PM are pink-noise files with a -12dB
signal
level. 11PS is independent stereo channels and 12PM is the same
signal
on both channels - the left channel of 11PS. These are not
realistic
tests of compression of music, but they show something about the
internal
functioning of the programs. The compression ratios for these
pink noise
files do not contribute to the averages at the bottom of the
table.
It is unavoidably wide, so scroll sideways and print in
landscape.
The table alone, for those who want to print it, is available as an
HTML file
here: table.html.
| |
Shorten
Tony
Robinson | Wave
Zip
Gadget
labs
MUSI-
Compress | Wav-
Arc -4
Dennis Lee | Wav-
Arc -5
Dennis Lee | Pegasus
SPS
jpg.com | Sonarc
2.1i
Richard
P.
Sprague | LPAC
Tilman
Liebchen |
Wav-
Pack
3.6B
David
Bryant | Audio
Zip
Lin Xiao | Monkey
3.81B
Matthew
T.
Ashland | RKAU
1.07
Malcolm
Taylor |
| 00HIChoral |
37.23 | 44.81 | 36.49 |
34.73 | 36.69 | 40.91 |
39.57 |
41.77 | 40.28 | 38.98 |
33.28 |
| 01CESolo Cello | 42.01 |
44.71 |
41.98 | 40.44 |
41.14 |
41.53 | 40.33 | 41.38 |
40.52 |
39.61 | 39.18 |
| 02BEOrchestra |
55.68 | 57.99 | 42.00 |
40.72 | 42.43 | 53.15 |
40.55 |
43.89 | 43.48 | 39.86 |
39.01 |
| 03CCBallet | 58.28 |
60.29 |
57.32 | 54.58 |
56.52 |
55.97 | 54.31 | 56.51 |
55.20 |
53.82 | 52.80 |
| 04SLSoftw.
Synth. | 42.54 | 45.23 | 42.02 |
39.64 | 40.70 | 40.99 |
39.61 |
41.88 | 40.65 | 38.32 |
33.06 |
| 05BMClub Techno | 74.07 |
75.43 |
69.51 | 68.45 |
70.70 |
72.91 | 68.45 | 69.75 |
69.34 |
66.81 | 66.60 |
| 06EBRampant
Techno | 68.50 | 69.56 | 66.95 |
66.23 | 67.67 | 68.97 |
67.02 |
66.48 | 65.80 |
66.30 | 65.88 |
| 07BIRock |
65.04 | 66.54 | 62.07 |
58.79 | 62.48 | 59.50 |
57.59 |
61.78 | 58.36 | 57.15 |
56.95 |
| 08KYPop | 74.36 |
75.28 |
71.39 | 70.41 |
72.08 |
71.13 | 69.55 | 71.76 |
69.47 |
68.09 | 68.07 |
| 09SRIndian
Classical
1 | 53.54 | 56.11 | 46.70 |
44.63 | 52.39 | 51.99 |
44.45 |
46.58 | 47.76 | 43.41 |
43.89 |
| 10SIIndian
Classical
2 | 58.60 | 61.50 | 56.12 |
50.99 | 53.46 | 50.99 |
49.73 |
54.34 | 50.70 | 49.24 |
49.23 |
| 11PSPink noise | 86.70 |
89.06 |
86.25 | 86.21 |
86.42 |
87.13 | 86.15 | 86.54 |
85.87 | 86.45 |
85.49 |
| 12PMPink
noise
mono | 86.71 | 89.06 |
43.15 | 43.14 |
43.27 |
87.14 | 43.09 | 46.29 |
78.32 |
46.24 | 42.75 |
Average size
Tracks 00 - 10 |
57.26 | 59.77 | 53.87 | 51.78 |
54.20 | 55.28 |
51.92 |
54.19 |
52.87 |
51.05 |
49.81 |
Average ratio
Tracks 00 - 10 |
1.746 |
1.673 | 1.856 |
1.931 |
1.845 |
1.809 |
1.926 |
1.845 |
1.891 |
1.959 |
2.008 |
| | Shorten |
WaveZip | WaveArc
-4 | WaveArc
-5 | Pegasus
SPS | Sonarc | LPAC | Wave
Pack | Audio
Zip | Monkey | RKAU |
Time to compress
3min
20sec Kylie pop track
(500 MHz Celeron) | 0:17 | 0:22
| 0:30
| 4:37
| 1:42 | 66:00 |
1:18 | 0:21 | 6:26 | 0:28 | 3:14 |
The compress time tests were performed with a 500MHz
Celeron
with 128MB of RAM and a 13Gig IDE hard disc. It took 7 seconds to
copy
the test file (00ky.wav 35.9 MB) from and to the disc. These
figures
should be regarded as accurate to only +/- 20%. The test files are
described below. 6 second 1 Megabyte
sample
waveforms are provided. The .wav files are stored in a directory which
is
not linked to exactly here, to stop search engines downloading them.
The directory
is /audiocomp/lossless/wav/ . Type this into your
browser
if you wish to download .wav files. Compression of these 6
second
samples will no-doubt produce different ratios then compressing the
entire
file, due to variations in the sound signal from moment to moment.
After I did these tests, I discovered some non-ideal aspects of
two
files:
- The Orchestra track was in fact mono - both
channels were
almost identical.
I think it was an old analogue recording.
- The Ballet file
(Can Can) had 12 seconds of silence at the end.
I have not changed them, since they are the same files as I used in
1998.
Description
of audio track
(Size Megabytes) | Average
level dB | Smallest
file size
as ratio
of original | Length
min:sec | Comments |
Source |
| Choral -
Gothic Voices: Hildegard
von Bingen: Columbia aspexit (00HI.wav 55.9MB) | -29.5 | 34.7% | 5:17 | | A
Feather on the Breath of
God Hyperion CDA66039 |
| Solo cello - Janos Starker J.S.
Bach: Suite
1 in G Major (01CE.wav 173.2MB) | -20.4 | 40.3% | 16.45 | | Sefel SE-CD 300A (Out of print
in 2005.)
|
| Orchestra - Beethoven 3rd Symphony (02BE.wav
43.6MB) | -21.1 |
40.6% | 4.07 | Mono | Berlin Philharmonic Music and
Arts
CD520, from a Classic CD magazine issue 54 cover disc. |
| Ballet -
Offenbach, Can Can (03CC.wav
24.4MB) | -14.6 |
54.3% | 2.18 | 12 sec
silence | Unknown orchestra, Tek
(Innovatek
S.A. Bruxelles) 93-006-2 |
| Software synthesis: my "Spare Luxury"
Csound
binaural piece (04SL.wav 85.0MB) | -20.5 | 39.6% | 8.02 | | I made this in 1996. It
has not been released on CD.
|
| Club techno - Bubbleman (Andy
Van): Theme
from Bubbleman (05BM.wav 59.1MB) | -11.7 | 68.5% | 5.35 | | Vicious Vinyl Vol 3 VVLP004CD |
| Rampant trance
techno - ElBeano (Greg
Bean): Ventilator(06EB.wav 44.0MB) | -14.3 | 65.8% | 4.09 | | Earthcore EARTH 001 |
| Rock - Billy
Idol, White Wedding
(07BI.wav
88.9MB) | -17.3 |
57.6% | 8.23 | | Chrysalis
CD 53254 |
| Pop
- Kylie Minogue, I Should be so
Lucky (08KY.wav 35.9MB) | -14.9 | 69.5% | 3.23 | | Mushroom TVD93366 |
| Indian classical
(mandolin and mridangam)
-
U. Srinivas:Sri Ganapathi (09SR.wav 71.7MB) | -12.1 | 44.4% | 6.45 | | Academy
of Indian Music
(Sandstock)
Aust.SSM054 CD |
| Indian classical (sitar and tabla) PT.
Kartick
Kumar & Niladri Kumar,: Misra Piloo (10SI.wav 89.4MB) |
-19.4 | 49.7% | 8.27 | | OMI
music D4HI0627 |
| Pink noise stereo (11PS.wav) |
-12.2 | 85.8% | 1.00 | | |
| Pink noise mono
(12PM.wav) | -12.2 |
43.1% | 1.00 | | |
The
10
programs
I tested
Shorten
Tony
Robinson WaveZip
Gadget
labs
(MUSI-Compress)
WavArc Dennis Lee
Pegasus SPS jpg.com
Sonarc
2.1i Richard P. Sprague
LPAC Tilman
Liebchen
WavPack
3.1 David
Bryant
AudioZip
Lin
Xiao Centre for Signal Processing,
Nanyang
Technological University, Singapore
Monkeys Audio 3.7
Matthew
T. Ashland
RKAU
Malcolm Taylor
FLAC Josh Coalson (Not
tested
yet.)
Any program listed as running under Windows 95 or 98 will presumably
run under
Windows ME, NT, 2000, XP etc.
Shorten Tony
Robinson
| Homepage |
http://www.softsound.com/Shorten.html |
| email | info@softsound.com |
| Operating systems | MS-DOS, Win9x. |
| Versions and
price | Win9x and demos free. More
functional MS-DOS
and
Win9x version available for USD$29.95. |
| Source code available? |
(In the past.) |
| GUI / command
line | GUI & Command line. |
| Notable features | High speed. |
| Real-time
decoder | In paid-for version. |
| Other features | - Near-lossless compression available.
- Shorten "supports compression of Microsoft Wave format
files
(PCM, ALaw and mu-Law variants) as well as many raw binary formats".
- Paid-for version includes:
- Batch encoding and
decoding.
- Creation of self-extracting encoded files.
- MS-DOS
Command line encoder/decoder.
|
| Theory of operation | A 1994 paper by Tony Robinson is available at
from this
Cambridge University site. |
| Options
used for tests | GUI program: "lossless". |
Technical background to the program is
at: http://svr-www.eng.cam.ac.uk/reports/abstracts/robinson_tr156.html
. I tested version "2.3a1 (32 bit)" as reported in the GUI
executable.
This was from the shortn23a32e.exe installation file.
Seek
information in Shorten files, and other programs which
compress
to the Shorten file format
There is another version of Shorten, "shortn32.exe" V3.1 at: http://etree.org/shncom.html.
etree.org is concerned with lossless compression for swapping DAT
recordings
of bands who permit such recordings. This is an MS-DOS executable
which
reports itself (with the -h option) as: shorten:
version 3.1: (c) 1992-1997 Tony
Robinson
and SoftSound Ltd
Seek extensions by Wayne Stielau
- 9-25-2000
This adds extra data to the file, or as a separate file,
to enable
quick
seeking within a file for real-time playback. It compresses and
decompresses.
I was unable to get it to compress without including the seek data, so
I did
not test it. I assume its performance is the same as the
program
I obtained from Tony Robinson's site.
Another program based
on Tony Robinson's Shorten is by
Michael
K. Weise - a Win98/NT/2000 GUI program called "mkw Audio Compression
Tool
- mkwACT" http://etree.org/mkw.html
. This generates compressed Shorten files with seek information.
It
can also compress to MP3 using the Blade codec. I tried
installing
the "version 0.97 beta 1" of this program, but there was an error.
Real-time
players for Shorten files
In addition to the real-time player included in the full (paid-for)
version
of Shorten, there is a free plugin for the ubiquitous Windows MP3 (etc.
&
etc.) audio player Winamp http://www.winamp.com
. The plug-in - ShnAmp v2.0 - http://etree.org/shnamp.html.
This uses the special files with seek information produced by the
programs
mentioned above. There is a functionally similar real-time player
program for Xmms the X MultiMedia System (Linux: and other
Unix-compatible
operating
systems):xmms-shnwhich is freely available, with source code,
from: http://freeshell.org/~jason/shn-utils/xmms-shn/
.
WaveZip
Gadget labs (MUSICompress)
| Homepage |
WaveZip http://www.gadgetlabs.com
but see note below on availability.
MUSICompress http://hometown.aol.com/sndspace
|
| email | None. |
| Operating systems | Win9x. (MUSICompress command line demo
program
runs in DOS box under any version of Windows.)
|
| Versions and price | Win9x evaluation version is free. A
paid-for
24 bit upgrade was available, but Gadget Labs has now gone out of
business.
(MUSICompress command line demo program is free to use.) |
| Source code available? |
No, but see the Al Al Wegener's Soundspace
site (below)
for information and source code regarding the MUSI-Compress algorithm. |
| GUI / command line | GUI. |
| Notable features | High speed. Handles 8 and 16 bit .WAV
files
in stereo and mono. Also supports ACD (Sonic Foundry's ACID) and
BUN
(Cakewalk Pro). |
| Real-time decoder | No. |
| Other features | Very handy file selection system |
| Theory of operation | Soundspace Audio's page for their MUSICompress
algorithm: http://hometown.aol.com/sndspace
See notes below. |
| Options
used for tests | There are no options.
(But see note
below on
commandline version of MUSICompress.) |
On
1 December 2000, Gadget Labs ceased trading and put some of its
software
in the public domain, with the announcement:
"We
regret to announce that Gadget Labs is no longer in
business.
We sincerely appreciate the support from customers during the last 3
years,
and we regret that we didn't meet with enough success to be able to
continue
to deliver our products and service. This web site includes
technical
information and software drivers that are being placed in the public
domain.
Please note that usage of the information and drivers contained here is
at
the user's sole discretion, responsibility, and risk."
Gadget Labs was primarily known for its digital audio interface
cards.
A Yahoo Groups discussion group regarding Gadget Labs is here. The
WaveZip
page at their site (wavezip.htm) has disappeared. There is no
mention
of WaveZip at their site at present. For now, I have placed
the
evaluation version 2.01 of WaveZip in a directory here: WaveZip/ . It is 2.7 megabytes.
In October 2001, Al Wegener wrote to me to point out the command line
demo
version of MUSICompress which is available for free (subject to
non-disclosure
and no-dissassembly) at his site. He wrote: Even
though the console interface is not nearly as
nice
as WaveZIP was, people can still submit WAV-format files to
this
PC app and both compress and decompress their files. This version
also
supports lossy compression, where users can play with a decrease in
quality
(one LSB at a time), vs. an increase in compression ratio.
By the way, I've gotten several new customers
recently
that use MUSICompress specifically because it's fast. On many of
these customers' files, an extra 10% compression ratio just isn't worth
a
20x wait.
MUSI-Compress Theory
The information sheet at: http://members.aol.com/sndspace/download/musi_txt.txt
indicates that MUSI-Compress is capable of reducing rock recordings to
between
60 and 70% of their original size. An informative paper from the
developer,
Al Wegener, is available in Word 6 format from the Soundspace
site.
MUSICompress is written in ANSI C using integer math only. It has
been
ported to at least two DSPs and is used in the WaveZIP program (see
below).
There is also a Matlab version, and the documentation which comes with
this
indicates that MUSICompress typically uses: Compression
requires between 35 and 45 instructions per
sample.
Expansion requires between 25 and 35 instructions per sample
According to Al Wegener, like other commercial lossless audio
compression
algorithms, MUSICompress uses a predictor to approximate the audio
signal
- encoding the prediction data in the output stream - and then computes
a
set of difference values between the prediction and the actual
signal.
These difference values are relatively small integers (in general) and
these
are compressed using Huffman coding and sent to the output
stream.
The compress and decompress functions can apparently be implemented in
hardware
with 4,700 gates and 20,500 bits of RAM (compress) and 3,800 gates and
1,500
bits of RAM (decompress) - which sounds pretty snappy to me.
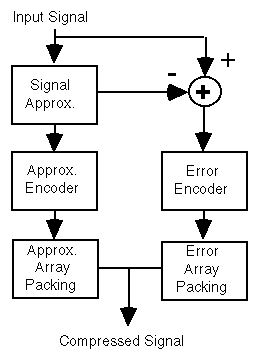 | The diagram to the left, from the
abovementioned
paper, depicts the approach taken by all the compression algorithms
reviewed
on this page. The raw signal is approximated by some kind of
"prediction"
algorithm, the parameters of which are selected to produce a wave quite
similar
to the input waveform. Those parameters are different for each
frame
(say 256 samples) of audio and are packed into a minimum number of bits
in
the output file (or stream, in a real-time application).
Meanwhile,
the difference between the "predicted" waveform and the real signal is
packed
into as small a number of bits as possible. Often, the "Rice"
coding
(AKA Rice packing) algorithm is used, but MUSI-Compress uses Huffman
packing
instead. Some of the material mentioned below contains more
detailed
theoretical descriptions of Rice packing and other algorithms - and I
have
my own explanation below. This diagram
is relevant to all the lossless algorithms I
know
of. (I worked on my own algorithm which worked on different principles
for
a while - but it did not work out well. A good "prediction"
system is
crucial.) The predictor is replicated in the decoder - and it
must work
from prediction parameters and the previously decoded samples.
The
predicted value is added to the "error" value to create the final
exactly
correct value for that sample. Then the prediction algorithm is
run
again, based on the newly decoded sample and some previous ones, to
predict
the next sample. |
WavArcDennis
Lee
| Homepage |
Unknown - but the program is available here: wavarc/.. |
| email |
Unknown. |
| Operating
systems | MS-DOS. (ie, in an MS-DOS window
in Win9.x.) |
| Versions and price | Free. |
| Source code
available? | No. |
| GUI / command line | Command line. |
| Notable features |
Potentially very high compression.
Multiple
files stored in one archive. |
| Real-time
decoder | No. |
| Other features | High compression ratio. Selectable
speed/compression
trade-off. Compresses WAV files and stores all other files without
compression
in the archive. |
| Theory of operation | ? |
| Options
used for tests | "a -c4" and "a -c5". |
Dennis Lee's Waveform Archiver is a freeware
command-line program
to
run under MS-DOS or in a Windows command line mode. It can store
multiple
.WAV files in a single archive.
Dennis Lee's web page: http://www.ecf.utoronto.ca/~denlee/wavarc.htm
disappeared sometime in 1999. Emails to that site (University of
Toronto)
enquiring about him have not resulted in any replies.
No source
code was available, and there was no mention of what
algorithms
are used. This program was made available on a low-key basis -
but
its performance in "compression level 5" mode significantly exceeds the
alternatives
that I was aware of when I did my first rounds of tests in late
1998.
When compressing, I found that the report it gives on screen about the
percentage
file size is sometimes completely wrong. I tested version 1.1 of
1 August
1997.
Dennis told me by email on 4 December 1998 that he had
done a lot
of
work on version 2.0 of Waveform Archiver - but is not sure when it will
be
finished:
Shortly before completing WA v2.0 I became
involved with
another
project
full-time, and haven't been able to work on WA
since. WA
v2.0
has some
significant improvements including: 1)
Faster at all compression settings.
2) -c6 codec
(slightly more optimal than v1.1's -c5).
3) A new -c5
that's much faster (about half the speed of
-c4).
This new codec is both backward and
forward
compatible
with v1.1's -c5.
4) Lossless compression for non-audio
files (provided by
zlib).
5) Several bug fixes including the incorrect
compression
status
on
large files.
I hope to
continue work on WA when I find the time.
WavArc began life in 1994, as explained in wavarc/WA.TXT
. I would be very glad to hear of Dennis Lee. I did an
extensive
web search in November 2000, but found no leads.
Pegasus
SPSjpg.com
| Homepage |
http://www.jpg.com/products/sound.html |
| email | sales@jpg.com |
| Operating systems | Win9x. |
| Versions and
price | Full version USD$39.95.
Evaluation version limited to 10 compressions. |
| Source code available? |
No. |
| GUI / command
line | GUI. |
| Notable features | WAV files, 8 and 16 bit, stereo and mono. |
| Real-time decoder | No. |
| Other features | Batch compression in paid-for version. |
| Theory of operation | http://www.jpg.com/imagetech_els.htm
for generalised ELS algorithm. |
| Options
used for tests | There are no options. |
In 1997 Krishna Software Inc. http://www.krishnasoft.com.
wrote a
lossless audio compression program for Windows. The program has
some
limited audio editing capabilities and several compression modes, but
the
most significant lossless compression algorithm - ELS - comes from
Pegasus
Imaging, http://www.jpg.com who seem
to have
developed it initially for JPG image compression. The SPS program
is
available from both companies.
Pegasus-SPS provides four
lossless compression modes and has the
ability
to truncate a specified number of bits for lossy compression. I
used
the default and highest performance "ELS-Ultra" algorithm for my
tests.
This was reasonably fast and produced results a fraction of a percent
better
than the next two best performing algorithms. When the compression
function
is working, this program seems to use virtually all the CPU cycles - at
least
under Windows 98 - so don't plan on doing much else with your computer!
Some information on ELS - Entropy Logarithmic Scale - encoding is
at: http://www.pegasusimaging.com/imagetech_els.htm
this leads to a .PDF file which has a scanned version of a 47 page 1996
paper
explaining the algorithm: "A Rapid Entropy-Coding Algorithm" by Wm.
Douglas
Withers.
I tested version 1.00 of Pegasus-SPS.
Sonarc 2.1i Richard P. Sprague
| Homepage |
None. |
| email |
None. |
| Operating
systems | MS-DOS. |
| Versions and price | Was shareware, but author is
uncontactable. |
| Source code available? |
No. |
| GUI / command
line | Command line. |
| Notable features | |
| Real-time
decoder | No. |
| Other features | |
| Theory of
operation | ? |
| Options
used for tests | "-x -o0" = use
floating point and for
each
frame, search for the best order or predictor. |
Sonarc, by Richard P. Sprague was developed up until 1994. His
email
address was "76635.652@compuserve.com" but in December 1998,
this
address was no longer valid. Sonarc has quite good compression rates,
but
it is very slow indeed.
There is an entry for it in the speech
compression FAQ http://www.speech.cs.cmu.edu/comp.speech/Section3/Software/sonarc.html
. Sonarc is also listed in Jeff Gilchrist's magnificent MS-DOS/Windows
"Archive
Comparison Test" site http://compression.ca/act/act-index.html
which gives an FTP site for the program: ftp://ftp.elf.stuba.sk/pub/pc/pack/snrc21i.zip
. This is the program I tested: version 2.1i. You can get a copy
of
it here: sonarc/ . The programs are MS-DOS
executables,
dated 27 June 1994. The documentation file, with the shareware
arrangements
and author's contact details is here: sonarc/sonarc.txt
. (A page of links regarding speech coding and the like: http://www.answerconnect.com/articles/speech-resources
.)
LPAC Tilman
Liebchen
| Homepage |
http://www.nue.tu-berlin.de/wer/liebchen/lpac.html
|
| email |
|
| Operating systems | Win9x/ME/NT/2000, Linux, Solaris. |
| Versions and price | Free. |
| Source code
available? | Tilman Liebchen writes that he
is
contemplating some
form of availability, and that "the LPAC codec DLL can be
used
by anyone for their own programs. I do not supply a special documention
for
the DLL, but any potential user can contact me.". |
| GUI / command line | GUI and command line. In the future (Dec
2000)
the LPAC codec DLL will operate as part of the Exact Audio Copy CD ripper. |
| Notable features | 8, 16, 20 and 24 bit support. |
| Real-time decoder | Yes, and a WinAmp plug-in. |
| Other features | High compression ratio. CRC (Cyclic
Redundancy
Check) for verifying proper decompression. |
| Theory of operation | Tilman Liebchen writes "adaptive prediction
followed
by entropy coding". |
| Options
used for tests | Extra High Compression,
Joint Stereo and no
Random
Access. |
Tilman Liebchen is
continuing to actively develop LPAC, the
successor
to LTAC which I tested in 1998.
The results shown here are for the "Extra High Compression" option with
"Joint
Stereo" and no "Random Access". The Random Access is to aid
seeking
in a real-time player, and adds around 1% to the file size. But
see
the sizes9.txt for the actual file sizes. In all cases not using
the
"Joint Stereo" option produced files of the same size or larger.
On
17 January, Tilman wrote:
The new LPAC Codec 3.0 has
just been released. It offers
significantly
improved compression ("medium" compression is now better than "extra
high" compression was before) together with increased speed (approx.
factor 1.5 - 2). I would be lucky if you could test the new codec and
put the results on your page.
I haven't tested it yet.
WavPack
3.1 David Bryant
| Homepage |
http://www.wavpack.com |
| email | david@wavpack.com |
| Operating systems | MS-DOS |
| Versions and
price | Free. Version 3.1 and 3.6
Beta. |
| Source code available? |
No. |
| GUI / command
line | Command line. |
| Notable features | High speed. |
| Real-time
decoder | WinAmp plugin currently being
developed. |
| Other features | Compresses non .WAV files, including Adaptec
.CIF
files for an entire CD.
Nice small distribution file < 82 kbytes. |
| Theory of operation | http://www.wavpack.com/technical.htm |
| Options
used for tests | No options affected the
lossless mode. |
I tested version 3.6
Beta of WavPack, using the -h option for the
high
compression mode which Dave Bryant added in 3.6. WavPack is
freely
available, without source code but with a good explanation of the
compression
algorithm. It is intended as a fast compressor with good
compression
ratios for .wav files. Compression and decompression rates of 8
times
faster than audio are achieved on a Pentium 300 MHz machine. The
algorithm
makes use of the typical correlation which exists between left and
right
channels in a stereo file. Two additional features are lossless
compression
of any file, with high compression for those containing audio (such as
CD-R
image files) and selectably lossy compression.
AudioZip
Lin Xiao Centre for Signal
Processing,
Nanyang Technological University, Singapore
| Homepage |
Was:
http://www.csp.ntu.edu.sg:8000/MMS/MMCProjects.htm
This is now defunct. Lin Xiao will let me know of a new
site
soon. (17 July 2002) |
| email |
Lin Xiao (Dr) Previously at EXLIN@ntu.edu.sg
He
is now longer with the University. Please contact me if you want
his
email address. |
| Operating systems | Win9x. |
| Versions and
price | Free. |
| Source code available? |
No. |
| GUI / command
line | GUI. |
| Notable features | High compression ratio. |
| Real-time decoder | No. |
| Other features | |
| Theory of
operation | "LPC with Rice encoding." |
| Options
used for tests | Maximum. |
The current version of AudioZip is rather slow - at least
at the
Maximum
compression mode, which I used in these tests. Its user interface is
quite
primitive, for instance it is necessary to manually enter the name of
each
compressed file. However Lin Xiao writes that he and his team are
working
to make AudioZip faster and more user friendly. See the note
below in
the RKAU section on how AudioZip and RKAU achieved the highest
compression
ratios for the pink noise file.
Monkey's
Audio 3.7 - 3.81 Matthew T. Ashland
| Homepage |
http://www.monkeysaudio.com |
| email | email@monkeysaudio.com |
| Operating systems | Win9x. |
| Versions and
price | Free. |
| Source code available? |
"Freely available source code, simple SDK and
non-restrictive
licensing - other developers can easily use Monkey's Audio in their own
programs
-- and there are no evil restrictive licensing agreements."
|
| GUI / command line | GUI and command line. Encoder can be
used by Exact Audio Copy
CD ripper.
|
| Notable features | High speed and high compression. |
| Real-time decoder | Standalone program and plugins for Winampand Media Jukebox.
Also,
apparently available as a plugin for Windows Media Player: http://www.mediaxw.org .
|
| Other features | CRC checking. Includes ID3 tags as used in MP3
to
convey information about the track. Can be used as front end for
other
compressors, including WavPack, Shorten and RKAU. Compresses WAV
files,
mono or stereo, 8, 16 or 24 bits. |
| Theory of operation | Adaptive predictor followed by Rice coding.
http://www.monkeysaudio.com/theory.html |
| Options
used for tests | Command line version
-c4000. |
I tested the command line
3.81 Beta 1 commandline-only version of
Monkey's
Audio, using the -c4000 option for highest compression. A
separate
renamer program is handy for changing the extension of file names - it
can
recurse into sub-directories. Monkey's Audio is actively being
developed
- in April 2002, the version was 3.96.
RKAU Malcolm
Taylor
| Homepage |
http://rksoft.virtualave.net/rkau.html |
| email | mtaylor@clear.net.nz |
| Operating systems | Win9x. |
| Versions and
price | Free. |
| Source code available? |
No. |
| GUI / command
line | Command line. (But Monkeys Audio can
be a GUI
front
end.) |
| Notable features | High compression. |
| Real-time decoder | Winamp
plugin. |
| Other features | Selectable lossy compression modes.
Can include real-time seek information for use with realtime players. |
| Theory of operation | ? |
| Options
used for tests | -t- -l2
-t- -l2 -s-
-t- -l3
-t- -l3 -s- |
I tested the v1.07
version, with options -t-" to not include
real-time
tags. Malcolm told me that the highest compression option "-l3"
sometimes
produced compression lower than "-l2", so I tried both options.
Likewise
the program's default behaviour of assuming there is something in
common
with both stereo channels does not always lead to the best
compression.
I tried RKAU with and without the -s- option, giving me four sets of
file
sizes. See ( oops - this file has gone missing:
analysis-rkau-107.html
) for these results and the "best-of" set chosen from the four
options.
The best-of set is reproduced below. These are the figures I have
used
in the main comparison table.
| | With or without
-s-
to disable
separate stereo channels | Either -L2 or -L3 | Best of RKAU 1.07 -t-
with
or without -s- and at either -l2 or -l3 | %
|
| 00HI | -s- |
L2 |
18,610,940 |
33.28 |
| 01CE | |
L3 | 69,471,291 | 39.18 |
| 02BE | |
L3 | 17,001,008 | 39.01 |
| 03CC | |
L3 | 12,879,953 | 52.80 |
| 04SL | -s- |
L3 | 28,109,211 | 33.06 |
| 05BM | |
L3 | 39,382,534 | 66.60 |
| 06EB | |
L2 | 28,985,245 | 65.88 |
| 07BI | |
L3 | 50,598,306 | 56.95 |
| 08KY | |
L3 | 24,435,044 | 68.07 |
| 09SR | | L2 | 31,464,353 |
43.89 |
| 10SI | -s- | L2 | 44,015,255 | 49.23 |
| 11PS | -s- |
L3 | 9,048,056 | 85.49 |
| 12PM | | L2 | 4,524,830 |
42.75 |
| Average
size00 - 09 | |
| | 49.812 |
| Average
ratio | | | | 2.00755 |
Note
that the average file size and compression ratio is based on
the
best achievable after compressing each file in four ways and manually
choosing
the smallest file size - something which is not likely to be practical
for
everyday use. It shows that RKAU has potentially better
compression
ratios than other programs for the files I tested, but that at present,
the
program is not smart enough to choose the best approach for each file.
The best results with any one option were for "-l2" (with -t- and
without
-s-). The average file size was 50.132% and the average
compression
ratio was 1.99475.
Malcolm suggests that other programs would
benefit from correct
choice
of whether or not to treat the stereo channels separately, or to treat
them
together (I guess compressing L+R as one channel and L-R as the other,
presumably
quieter channel). You can see by the results for the stereo and
"mono"
(both stereo channels the same) which programs are taking notice of
stereo
correlations. RKAU does this by default, but sometimes it would
be better
if it did not. Here are the options for each program:
| Program |
Default - does it
recognise
correlation between channels? | Option to control
Joint Stereo? | Comments |
| Shorten | | No. |
|
| WaveZip
(Gadget Labs) | | No. | |
| WaveArc | Yes. | No. |
|
| PegausSPS |
Yes. | No. | |
| Sonarc | | No. | |
| LPAC | Yes. |
Joint Stereo is on by
default. | Best to use Joint Stereo - the results are the same
or
better
then without it. |
| WavPack |
| No. | |
| AudioZip | To some extent. | No. |
|
| Monkey
3.81 beta | Yes. | No. | |
| RKAU | Yes. | Yes:
-s- | -s- is sometimes better. -l2 is sometimes better than
-l3. |
I have not counted
the pink-noise results towards the
average
compression percentages/ratios, because they do not represent musical
signals,
it is interesting to see which algorithm achieves the highest
compression
ratio for the stereo pink noise file. This signal has no musical
pattern
in terms of spectrum or sample-to-sample correlation other than pink
noise
filtering of white noise to give a spectrum of -3dB per octave,
compared to
white-noise (each sample completely random) which has a flat frequency
response.
(For more on pink noise, see: dsp/pink-noise/).
This indicates that the RKAU and AudioZip's algorithms are highly
attuned.
FLAC
Josh
Coalson
| Homepage |
http://flac.sourceforge.net/
http://sourceforge.net/projects/flac |
| email | jcoalson@users.sourceforge.net |
| Operating systems | Win9x, Linux, Solaris - any Unix. |
| Versions and price | Free. |
| Source code
available? | Yes! GPL and
LGPL. Written
in
C. |
| GUI / command line | Command line. |
| Notable features | Open source, patent-free format and source
code for
codec. |
| Real-time decoder | Winamp and
XMMS
plugins. |
| Other features | Uses stereo interchannel correlation in
several possible
ways, including variants such as L, (R-L). Several predictor
algorithms
and two approaches to Rice coding of the residuals. All these can
be
used optimally per block. The current version of the codec uses
fixed
blocksizes, but the format enables them to be varied dynamically.
Provision
for metadata, such as ID3 tags. |
| Theory of
operation | http://flac.sourceforge.net/format.html |
| Options
used for tests | Not tested yet. |
FLAC (Free Lossless Audio Coder) was released in
an Alpha form on
10
December 2000. I have not yet tested it. There
are
a number of parameters which may affect compression ratios, so I will
try
a few combinations.
Please provide feedback!
Please let me know your suggestions for improving this
page,
particularly for correcting any problem with my description of the
programs
tested. I can't keep linking to every paper or page regarding
lossless
audio
compression, but I would like to link to he major ones. Mark
Nelson's
compression link farm below, is likely to be a
more complete
set of links.
If you like this page, please consider writing to Dr Lin
Xiao EXLIN@ntu.edu.sgwho
organised the
funding
for my work on it in November-December 2000.
With about 150
visits a day, this page is one of the most popular
on
my website.
Programs I did not test or report
on fully
Florin Ghido's OptimFROG is a program I first heard about in August
2002.
I have not investigated it, but it is a lossless audio
compression program
for Windows and Linux, with a WinAmp and XMMS (I don't know what it is)
plugin.
The source code does not appear to be available.
Two programs I tested briefly but have not reported on because their
performance
was not as good as any of those listed above: RAR (AKA Win-RAR) is a general purpose archiver,
with a
"Multimedia"
option: http://www.rarsoft.com
I tested version 2.80 Beta 1 with the "Best" and "Mulimedia" options -
the
results are in the spreadsheet. I
have not
added it to the table because, with a few exceptions, its compression
ratios
were worse than any of the programs listed in the table. RAR's
average
compression size was 61.219, giving a ratio of 1.63347. RAR is a
shareware
program with an evaluation period and a USD$35 registration fee.
It
has versions in multiple languages for operating systems including
Windows,
MS-DOS, Mac, Linux and various other flavours of Unix. MKT http://home.att.net/~mkw/mkwact/
is a Windows drag-and-drop program with its own lossless compression
format
by Michael K. Weise, mkw@worldnet.att.net . As with RAR and DAKX
the
compression ratios were no better than those already in my table.
I
have added them to the spreadsheet
For MKT
0.97 Beta 1, the average compression size was 70.061, giving a ratio of
1.42732.
MKT can also act as a fron-end for encoding with LAME (a highly
regarded open-souce
MP3 encoder/decoder) and losslessly with Shorten, with or without
real-time
seeking information. In doing so, MKT can apparently recurse and
create
subdirectories.
Emagic have a lossless compressor Zap
for the
Macintosh,
with decompression on Mac and Windows: http://www.emagic.de/english/products/software/zap.html
. I did not test it because I do not have a Macintosh.
The
DAKX system, described more fully below, has a
Mac-only shareware
version and a Windows 9x version 1.0.
Merging Technology's LRC
system has no demonstration
program: http://www.merging.com/products/lrc.htm.
WinAce http://www.winace.com/
(added in January 2003) is a general purpose non-open-source archiver
for
Windows, Linux and maybe other operating systems. It apparently
has
special modes for dealing with audio data and so achieves better
results
than most general purpose compression algorithms. This would be
convenient
for compressing and archiving entire directories of files, without
having
to fuss over the exact nature of them.
Links specific to lossless audio
compression
There are many more links regarding data
compression
of integers of varying lengths at the bottom of
this
page. Brian
Dipert's lossy and lossless
codec
project
>>> "There
is another system!"
- Colossus,
in The
Forbin Project. <<< http://www.commvergemag.com/commverge/extras/P178673.htm
This site tests several of the lossless codecs (encoder / decoder)
tested
here. In December 2000, these included MUSICompress
(WaveZip),
Shorten, WavPack and RAR. This is an ongoing project and the site
lists
several other lossless codecs, including MKT which I had not heard of
before.
This page has some excellent links to lossy and lossless codec sites!
When I looked at it this page was corrupt and displayed
incorrectly
on every browser I tried (Netscape,Mozilla,Opera) apart from Microsoft Internet
Explorer.
Search Engines
AltaVista Advanced - http://www.altavista.com/cgi-bin/query?pg=aq&text=yes
- returned 1,014 pages in December 2000 for the query:
lossless near (sound or audio) and
(compression
or "data reduction")
Click here
to repeat that search.
Mark
Nelson's
formidable compression resources and link farm
Author Mark Nelson maintains a fabulous set of pages of links to all
matters
compression. The index page is: http://datacompression.info/
Dr Dobb's
Compression Forum
http://www.ddj.com/topics/compression/
Mark Nelson's extensive resource at the Web abode of what used to be
known,
from 1976 as Dr. Dobb's Journal of Calisthenics and Orthodontia:
Running
Light Without Overbyte.
Usenet newsgroup
comp.compression
The FAQ for Usenet newsgroup comp.compression is at: http://www.cis.ohio-state.edu/hypertext/faq/usenet/compression-faq/top.html
If you don't have direct access (via NNTP) to a Usenet server
which
carries comp.compression, you can read the posts via the Web at:
http://groups.google.com/group/comp.compression
- and no doubt other such sites.
Mat Hans' thesis
Mat Hans http://users.ece.gatech.edu/~hans/
has written a magnificent PhD thesis on lossless audio
compression.
It is in PDF format and is available zipped from his web site.
(Actually,
PDF is highly compressed - its generally better not to compress them
with
another algorithm.) The thesis looks at both lossy and lossless
algorithms.
In the lossless area, Hans tests and explores the inner workings of
many
lossless audio compression algorithms.
DAKX
A new algorithm suitable for lossless or lossy compression of audio and
other
similar signals has been developed by DAKX in North Carolina: http://www.dakx.comThe algorithm is
patented
in the US: http://www.delphion.com/details?&pn=US05825830__
. My impression is that it focuses on the most efficient way of storing
the
differences between one sample and another. This largely concerns
setting
a bit-length to hold each diff value in the output stream, with snappy
ways
of increasing or decreasing that bit-length. There areMacintosh
executables for audio files. One (v1.1) is shareware for
USD$40. D. A. Kopf, DAKX's developer, wrote to me and asked me to
link to
and
test a Windows v1.0 version of DAKX. This is not as developed as
the
later Mac version, but it has the same compression performance.
The
program is at: http://dakx.com/aps/daxwav32.zip
is free to use. His email dakx-1.txt contains
a brief
description or DAKX's algorithm.
I have not listed DAKX's
compression performance in the table
above,
since it does not in general surpass any of those listed - and the
table
is already rather wide. I have added its results to the spreadsheet. Its average file size and
compression
ratio are 61.444% and 1.62749 respectively. These tests were done
in
16 bit mode with the slider on the right at the higest position for "M"
maximum
complression. D. A. Kopf wrote to me that the Windows
version's
maximum compression is not quite as good as the Macintosh
version. Compressing
one section of a test file (03CC.wav) he found that the Windows and
Macintosh
file sizes were 57.03% and 56.50% respectively.
Quite apart
from its use as a compressor, this Windows version 1.0
of
DAKX (and, I imagine the later Mac version) has a most fascinating
and
eductational function: It can play back WAV files with
truncation
from 16 (no truncation) down to 2 bits, with the truncation
selectable
by a slider in real-time!! Be sure to increase the size of
the
window by dragging the bottom right corner - this makes the file
selection
business easier. Click on the Play button and then double-click
on
the file you want to listen to. This is a handy test tool for
those
who swear they need 24 bits! In many listening situations, it is
hard
to hear 14 bit truncation. This playback function makes a Jim
Dandy
fuzzbox too!
DVD-AUDIO and Meridian Lossless
Packing
(MLP)
I have not been following this at all, due to shortage of time, my
belief
that there's nothing wrong with 44.1 kHz 16 bit digital audio when it
is
properly done, and my interest in binaural sound, rather than
multi-channel
surround sound. (Nonetheless, for mastering, 20 or even 24 bit
accuracy
would be handy.) Click here
to search Alta Vista Advanced text mode for material on "meridian
lossless
packing".
- Meridian's site: http://www.meridian.co.uk/m_news.htm
.
- A paper called "Coding High Quality Digital Audio "
available
in PDF format from http://www.meridian.co.uk/ara/jas98.htm
has some interesting arguments about why 16 bit 44.1 kHz audio is
supposedly
not good enough, and mentions lossless compression for 96 kHz 24 bit
digital
audio for DVD discs. This is part of the ARA Acoustic
Renaissance
for Audio project.
- Frequently Asked Questions about
Surround Sound : http://www.surroundassociates.com/fqmain.html
. More than 12 hours of 44.1 kHz 16 bit stereo with MLP will apparently
be
possible with DVD-A. It is extraordinary that there are still
plans
to add watermarking noise to material released on this potentially
impeccable
format!
- Dolby's Frequently Asked Questions about Dolby
Digital is
one
of the files available at: http://www.dolby.com/tech/
.
Various
other links
A large list of MS-DOS / Windows archiving programs, including some
real
antiques, is maintained by Jeff Gilchrist at his ACT Archive
Compression
Testsite: http://web.act.by.net/~act/
. There is a test there on lossless compression of 8 bit audio files,
but
I am really only interested in 16 bit stereo files, which are a very
different
thing.
Compression Pointers from Stuart Inglis: http://www.internz.com/compression-pointers.html
.
Seneschal http://seneschal.net/infoannex.htm?external
has an excellent set of links and papers regarding high sample-rate and
bit
resolution audio, including with new DVD audio formats. One
article
there by Seneshal's Oliver Masciarotte from the July 1998 Mix magazine,
discussing
various audio formats for DVD (DVD-Audio - which was then being
finalised)
and potentially lossless compression based the ARA proposal. In
June
99 there is an article interviewing a Dolby engineer about Meridian
Lossless
Packing as used in DVD-Audio.
Not a lossless algorithm, but a relatively low loss system used for
broadcasting
is Audio Processing Technology's 4:1 fixed rate apt-Xsystem.
http://www.aptx.com This is a
real-time,
high quality, low delay system (2.76ms for encode and decode combined)
- which
does not rely on psycho-acoustic models etc. The FAQ describes
it:
ADPCM as used by APT for its apt-X 4:1 compression algorithm
takes the digital signal and breaks it into four frequency sub bands
by means of a QMF digital filter. Each of these sub bands is
subsequently coded by means of predictive analysis; the coder predicts
what the next digital sample in the audio signal will be and subtracts
this
prediction from the actual sample. The resulting, small error signal is
transmitted to the decoder which then adds back in the prediction from
identical tables stored in the decoder. NO psycho-acoustic auditory
mask is used to throw away any of the original audio signal resulting in
a near lossless compression system.
In March 2001, a chap from APT wrote to me that the algorithm is
available
on a demo basis as a Windows DLL.
My work, an explanation of Rice
Coding
and an exploration of alternative coding strategies for generally short
variable
length integers
In November 1997 I spent some time pursuing an old interest
-
lossless compression of audio signals. I tried sending, for
instance,
every 32nd sample, and then sending those in between - sample 16, 48
etc.
- as differences from the interpolation of the preceding and following
32nd
sample. Then I would do the 8th samples which were missing, and
then
the 4th and then all the odd samples on the same basis. This
constitutes using interpolation between already transmitted
samples
as a predictor - and the results are not particularly promising.
I
also experimented using the highest quality MP3 encoding as a
predictor,
but even using LAME at 256 kbps, the difference between this (once
decoded
and aligned for shifts in the output waveform's timing) were quite
large.
The difference was generally broadband noise, with its volume depending
on
the volume of the input signal. This does not look like a
promising
approach either.
In December I figured out an improvement to
traditional "101 =>
000001"
Rice encoding. It turned out to be a generally sub-ovariation on
the
Elias Gamma code.
Here is a quick description of Rice and Elias
Gamma - and a link
to
an excellent paper on these and other funtionally similar codes.
Rice
Coding, AKA
Rice
Packing, Elias Gamma codes and other approaches
In a lossless audio compression program, a major task is to
store
a larege body of signed integers of varying lengths. These are
the "error"
values for each sample: they tell the decoder the difference between
its
predictor value (based on some variable algorithm working on previously
decoded
samples) and the true value of the sample. The coding methods here
all relate to storing variable length
integers,
in which the distribution is stronger for low values than for high.
I have not read the original paper:
R. F. Rice, "Some
practical
universal
noiseless coding techniques" Tech Rep. JPL-79-22, Jet Propulsion
Laboratory,
Pasadena, CA, March 1979. I have read various not-so-great
explanations of Rice
coding.
There seems to be several often-related algorithms which come under
this
heading.
Initially, there are Golumb codes, as per the paper:
S.W. Golomb, "Run-Length Encodings", IEEE Trans
Info.
Theory, Vol 12 pp 399Ð401 1966.
Golumb codes are a generalised
approach to dividing a number into
two
parts, encoding one directly and the other part - the one which varies
more
in length, in some other way.
Rice codes are a development of
Golumb codes. Here I will
deal
only with Rice codes of order k = 1, which is the same (I think) as
Golomb
codes of order m = 1.
The basic principle of Rice coding for k
= 1 is very
simple:
To code a number N, send N zeros followed by a one.
To send 0
(0 binary) with Rice coding, the output is 1.
To send 1 (1 binary) with Rice coding, the output is 01.
To send 4 (100 binary) with Rice coding, the output is 00001.
There
are other Rice codes for k = 2 and higher values, but they
are
not so straightforward and suffer from the problem of involving three,
four
or more bits even when sending a simple 0.
Terminology is a bit
of a problem, since there is a larger, more
complex
operation as part of a lossless audio compression algorithm (described
below)
which is often referred to as "Rice" coding or packing, but
technically,
the Rice coding (for k = 1) is nothing more than the above. I
will
refer to them collectively as Rice - but I think there should or must
be
a separate term for the more complex algorithm described below.
The following discusses how Rice (and later some other
algorthms)
is
used as part of a larger operation on multiple signed binary numbers -
the
"error" values in a lossless compressor algorithm. The "error"
values
are to be stored in the file in as compact form as possible. They
will
be used by the decoder to arrive at the final value for each output
sample,
by adding this "error" value to the output of the predictor algorithm,
which
is operating from previously decoded samples.
These "error"
numbers are generally small, but quite a few of them
are
large, due to the complex and unpredictable nature of sound.
Huffman
coding can also be used, and is used by some of the programs tested
here.
These error numbers are typically twos-complement
(signed) 16 bit
integer,
but their values are often small, say in the range of +/- a hundred or
so,
and so can be shortened to a 9 bit twos-complement integer. Some
may
be much larger - say +/- several thousand. Few are the full 16
bits,
but some may be. How do you compress this ragged assortment
of
numbers?
For these signed numbers, there is a preliminary step
of
converting
to positive integers with a right-affixed sign bit. Lets
use
some examples, which we will consider as a frame of 8 "error words" to
be
compressed.
Decimal 16 bit
signed
Sign
Integer
Integer with sign
integer
at right
+20 0000
0000 0001
0100
+ 1
0100
101000
+70 0000 0000
0100
0110
+ 100
0110
10001100
-5
1111 1111 1111
1011
-
101
1011
+129 0000 0000 1000
0001
+ 1000
0001
100000010
-300 1111 1110
1101
0100
- 1 0010
1100
1001011001
+12 0000
0000 0000
1100
+
1100 11000
+510 0000 0001 1111
1110
+ 1 1111
1110
1111111100
-31 1111
1111 1110
0001
- 1
1111
111111
The decimal and spaced-out 16 bit signed binary integer
representations
are to the left. Following that are the numbers converted into a
sign
and an unsigned integer, with leading zeroes removed. Then
those
integers have there corresponding sign bit tacked on to the right end,
with
negative being a "1".
This right column of binary numbers is
what we want to store in a
compact
form. The big problem is that their lengths vary dramatically.
The first part of the Rice algorithm is to decide a "boundary"
column,
in this set of numbers. To the right, the bits are generally an
impossible-to-compress
mixture of 1s and 0s. To the left, for some samples at least,
there
are some extra ones and zeros which we need to code as well. For
example,
by some algorithm (which can be complex and iterative for Rice coding
of these
numbers on the left) a decision is made to set the boundary so that, in
this
example, the right-most 6 bits (including the sign bit which has been
attached)
is regarded as uncompressible. These bits will be sent directly
to
the output file. Also, by some means, the decoder has to be told,
via
a number in the output file, to expect this six bit wide stream of
bits.
(The decoder already knows the block length, which is typically fixed,
so
when it receives 48 bits, in this case of an 8 sample frame, in the
context
of already having been told to expect 6 bits of each sample sent
directly,
then it knows exactly how to use these 48 bits. Typically
lossless
audio programs use longer frames, say several hundred samples.)
So
the body of data we are trying to compress is broken into two
sections:
101000
10 001100
1011
100 000010
1001 011001
11000
1111 111100
111111
or, more pedantically:
101000
10 001100
001011
100
000010
1001 011001
011000
1111 111100
111111
Sending the right block is straightforward - but
how to
efficiently
encode the stragglers on the left? (Note, "straggler" is my
term!)
Here they are, expressed as the shortest possible integer.
I
have added two columns for their decimal equivalent and for which of
the
8 samples they are:
Binary
Decimal
Straggler of
sample number
0
0 0
10
2 1
0
0 2
100
4
3
1001
9
4
0
0 5
1111
15
6
0
0 7
As mentioned above, the Rice algorithm (for k = 1) has a
simple
rule
for transmitting these numbers. Send the number or 0s as per the
value
of the number, and then send a 1 to indicate that this is the end of
the number.
(In other descriptions, a variable number of 1s may be sent with a
terminating
0.)
So to send straggler number 0, which has a value of 0, the
Rice
algorithm
sends (i.e. writes to the output file) a single "1".
To send
straggler number 0 (value 2) the Rice algorithm sends
"001".
Similarly, for straggler number 6, the Rice algorithm
sends
"0000000000000001".
To encode the above 8 stragglers, the
Rice algorithm puts out:
10011000010000000001100000000000000011
Now, seeing
strings of 0s in a supposedly compressed data stream
does
seem a little incongruous. As the Kingdom of Id's fearless
knight,
Sir Rodney was heard to say, when during a ship inspection he was shown
first
the head (lavatory) and then the poopdeck: "Somehow, I sense
redundancy
here.".
So I "invented" an alternative. Initially I
could find no
reference
to such an improvement on basic Rice (k = 1), but a more extensive
web-search
showed that my system was a sub-optimal variation on "Elias Gamma"
coding.
More efficient alternatives to Rice Coding - Elias
Gamma and other
codes
The code I "invented" is not exactly described in papers I
have
found, so I will give it a name here: Pod Coding because it
reminds
me of peas in a pod. Rice (k = 1) coding has the following
relationship between the
number
to be coded and the encoded result:
Number
Encoded result
Dec Binary
0
00000
1
1
00001
01
2
00010
001
3
00011
0001
4
00100
00001
5
00101
000001
6
00110
0000001
7
00111
00000001
8
01000
000000001
9
01001
0000000001
10
01010
00000000001
11
01011
000000000001
12
01100
0000000000001
13
01101
00000000000001
14
01110
000000000000001
15
01111
0000000000000001
16
10000
00000000000000001
17
10001
000000000000000001
18
10010
0000000000000000001 Rice coding makes most sense when most of
the numbers to be coded
are
small. This suits the "exponential" or "laplacian" distribution
of
numbers which typically make up the differences of a lossless audio
encoding
algorithm.
(Speaking very loosely here - where is a
reference on the
various
distributions and a graphic of their curves? Gaussian is a
bell-shaped
curve. Britannica has some explanations and diagrams: http://www.britannica.com/bcom/eb/article/2/0,5716,115242+8,00.html
. . . . . . the best reference I can find is from Tony Robinson's
paper:
http://svr-www.eng.cam.ac.uk/reports/ajr/TR156/node6.html
This includes some very helpful graphs.
One page: http://www.bmrc.berkeley.edu/people/smoot/papers/imdsp/node1.html
describes laplacian as being double-sided exponential.)
In
January 2002, Reg Dunn pointed me to an impressive reference
on
distibutions by Michael P. McLaughlin: http://www.causascientia.org/math_stat/Dists/Compendium.pdf
Here is the "pod" approach. The
example is probably easier to
understand
than the formal explanation:
Number
Encoded result
Dec Binary
0
00000
1
1
00001
01
2
00010
0010
3
00011
0011
4
00100
000100
5
00101
000101
6
00110
000110
7
00111
000111
8
01000
00001000
9
01001
00001001
10
01010
00001010
11
01011
00001011
12
01100
00001100
13
01101
00001101
14
01110
00001110
15
01111
00001111
16
10000
0000010000
17
10001
0000010001
18
10010
0000010010
Here is the formal definition. For 0,
send:
1
For 1,
send
01
For 2 bit numbers 1Z, send
001Z
For 3 bit numbers 1YZ, send
0001YZ
For 4 bit numbers 1XYZ, send
00001XYZ
For 3 bit numbers 1WXYZ, send 000001WXYZ
There's no problem for the decoder knowing how many bits
WXYZ etc.
to
expect - it is one less than the number of 0s which preceded the 1.
In two instances, "pod" coding produces one more bit than the Rice
algorithm.
In 4 instance it produces the same number of bits. In all other
case,
it produces less bits than the Rice algorithm.
Number
Rice
Pod
Benefit
Dec
Binary
bits
bits
0
00000
1 1
1
00001
2 2
2
00010
3
4
-1
3
00011
4 4
4
00100
5
6
-1
5
00101
6 6
6
00110
7
6
1
7
00111
8
6
2
8
01000
9
8
1
9
01001
10
8
2
10
01010
11
8 3
11
01011
12
8 4
12
01100
13
8 5
13
01101
14
8 6
14
01110
15
8 7
15
01111
16
8 8
16
10000
17
10 7
17
10001
18
10 8
18
10010
19
10 9
19
10011
20
10 10
20
10100
21
10 11
There would be few situations in which the loss of
efficiency
encoding
"2" and "4" would not be compensated by the gains in coding numbers
higher
than "5".
In the above example, the output of the Rice and
"Pod" algorithms
respectively
would be as follows, first broken with commas and then without:
Rice:
1,001,1,00001,0000000001,1,0000000000000001,1
"Pod":
1,0010,1,000100,00001001,1,000011111,1
Rice:
10011000010000000001100000000000000011
"Pod":
1001010001000000100110000111111
I imagine that "Pod" coding (the way it encodes each
straggler)
would
be suitable for sending individual signed and unsigned integer
values
in a compressed datastream, such as changes from one frame to the next
in
prediction parameters and the number of bits (width of the block to the
right
of the "boundary") to be send directly without coding,
"Pod" packing has the fortuitous property that the
number of bits
produced
is exactly twice the number of bits encoded - except for encoding "0"
which
produces 1 bit.
This should greatly simplify the algorithm in a
Rice-like system
for
deciding where to set the boundary between bits to be sent unencoded,
and
those stragglers to the left to be encoded with the "Pod" algorithm.
A practical implementation could determine the bit length for each
complete
"sample" (including its sign bit on the right) which is being
accumulated
in the array prior to coding. By maintaining a counter for
each
possible sample length, and incrementing the appropriate counter for
each
sample created, then an array of integers would result showing how many
10
bit numbers there were in the frame, how many 9 bit numbers and so on.
Since "Pod" coding produces precisely 2 bits for every input bit,
and
one bit if the input is 0, then as we move the boundary (between
"stragglers"
to the left and "direct send" bits to the right) to the right, we can
answer
the question of when to stop rather easily:
- Samples
which are not stragglers require 1 bit to code with
"Pod".
- No matter how long the straggler, moving the
boundary to
the
right (including the case of a "1" appearing as a straggler in the
column
immediately to the left of the boundary) will require 2 bits to encode
this
extra straggler bit.
- Moving the boundary to the right saves 8
bits (in this example)
by
reducing the number of bits to be sent without coding from the block to
the
right of the boundary.
The result is a simultaneous equation involving a potential cost in the
straggler
encoding part of N (the number of samples in the frame) and that cost
being
2 times the number of stragglers minus 1 times the number of
non-stragglers. Therefore, the break-even point is the boundary
position where 1/3
of
the samples have stragglers and 2/3 don't.
The optimal position
for the boundary is the one to the left of
the
position which would increase the number of stragglers to more than 1/3
of
the number of samples in the frame.
With the Rice algorithm,
this process is more complex (I think)
because
the exact number of bits to be sent depends on the exact values of the
stragglers,
not just their bit-length. Some papers give a simple formulae
based
on the values of all the samples to determine the optimal placement of
the
boundary.
I have not implemented or tested this "Pod" approach.
This approach would provide the most benefit over the "Rice"
approach
when the stragglers have relatively high values - which means when most
of
the samples are small and a few are much larger. Since "Pod"
outperforms
the Rice algorithm when the samples peak at around 16 or more times the
maximum
value which will fit to the right of the "boundary" and since, at a
guess,
the average of those samples which do not form stragglers would be
around
a half to a third of that value, this "Pod" approach would only have
benefits
for relatively "spiky" values.
To what extent this is true of
error samples to be encoded in a
lossless
audio algorithm, I can't say, but I would venture that it is is
proportional
to the unpredictability of the music.
Now it turns out that my
"pod" approach is a variation, and not
necessarily
the best variation, on "Elias Gamma" coding.
By far the best
paper I can find on Golumb, Rice, Elias and some
more
involved and novel codes is by Peter Fenwick ( http://www.cs.auckland.ac.nz/~peter-f/
)
Punctured Elias Codes for variable-length coding
of
the
integers
Peter Fenwick peter-f@cs.auckland.ac.nz
Technical Report 137 ISSN 1173-3500 5 December 1996
Department of Computer Science, The University of Auckland
peter-f@cs.auckland.ac.nz
This is available as a Postscript file at: ftp://ftp.cs.auckland.ac.nz/out/peter-f/
TechRep137.ps . I have converted it into a PDF file here: TechRep137.pdf. (Peter Fenwick wrote
to me
that this is fine.)
Peter Fenwick's purpose co-incides closely with our interest
- how
to
efficiently encode integers of varying lengths, when most of the
integers
are small.
He refers to a paper:
P. Elias, Universal
Codeword Sets and Representations
of
the Integers, IEEE Trans. Info. Theory, Vol IT 21, No 2, pp
194-203,
Mar 1975.
There is an abstract for this at: http://galaxy.ucsd.edu/welcome.htm
but no PDF. Peter Fenwick's paper describes:
- Golumb
and Rice codes of various orders.
- Elias gamma codes.
- Elias
delta codes.
- Elias omega codes, which are comparable to
Even-Rodeh codes
- Start-Step-Stop codes.
- Ternary
comma codes.
- His new "punctured" code.
- Comparisons
of all the above for different sizes of integer and
for
two probability density functions of actual files in a text compressor.
- A modified ternary comma code with slight improvement for low
numbers
and less efficiency for numbers higher than 15.
- Variable
radix gamma codes - a special, self-extending, case of
Start-Step-Stop
codes.
He describes the Elias Gamma (actually the Gamma symbol with a prime -
so
maybe Elias Gamma Prime) code as: Number
Encoded result
Dec
Binary
"Codeword"
1
00001
1
2
00010
010
3
00011
011
4
00100
00100
5
00101
00101
6
00110
00110
7
00111
00111
8
01000
0001000
Note that this does not include encoding for zero.
My "pod" approach is simply extending the above code with a 0 to
the
left of all the above codewords, and a "1" for encoding zero.
This
is not how Elias Gamma is normally extended to cover 0.
The
usual approach is to use the same pattern, but start at 0 rather than 1
for
the number range it encodes. This is known as "biased Elias
Gamma".
Here are the two codes alongside each other, with their benefits over
standard
Rice coding:
Two bugs in my table were pointed out to
me in July 2004 by
Carlos Mourao and fixed in October 2005. Carlos noted:
Always when the decimal input is a power of 2 minus one,
Elias Gamma coding will need two more bits than Pod
coding, then loosing to Pod in these situations.
Number
"Pod" Biased
Elias
"Pod" Biased Elias Gamma
Dec
Binary
Gamma
benefit benefit
0
00000
1 1
1
00001
01
010
-1
2
00010
0010
011
-1
3
00011
0011
00100
-1
4
00100
000100
00101
-1
5
00101
000101
00110
1
6
00110
000110
00111
1 2
7
00111
000111
0001000
2 1 (was 3)
8
01000
00001000
0001001
1 2
9
01001
00001001
0001010
2 3
10
01010
00001010
0001011
3 4
11
01011
00001011
0001100
4 5
12
01100
00001100
0001101
5 6
13
01101
00001101
0001110
6 7
14
01110
00001110
0001111
7 8
15
01111
00001111
000010000
8 7 (was 9)
16
10000
0000010000
000010001
7 8
17
10001
0000010001
000010010
8 9
18
10010
0000010010
000010011
9 10
Standard
Rice coding is clearly the best approach when most of the
numbers
to be encoded are small.
From the example above, here are the
"stragglers" encoded with
Rice,
my "Pod" extension to Elias Gamma, and the more usual approach: Biased
Elias
Gamma:
Rice:
10011000010000000001100000000000000011
"Pod":
1001010001000000100110000111111
Biased Elias Gamma:
1011100101000101010000100001
There are many potential
Start-Step-Stop codes - please read the
paper
for a full explanation. The reference for these is:
E.R.
Fiala, D.H. Greene, Data Compression with
Finite
Windows, Comm ACM, Vol 32, No 4, pp 490-505 , April 1989.
One such code, with an open-ended arrangment so it can be used for
arbitrarily
large numbers, rather than stopping at 679 as in the paper's Table 5,
is
what I would call {3, 2, N} Start-Step-Stop coding, where N is some
high
number to set a limit to the system. Number
range Codeword
to be coded
0 - 7
0xxx
( 4 bits total, 1 bit prefix + 3 bits data)
8
- 39
10xxxxx
( 7 bits total, 2 bit prefix + 5 bits data)
40 -
167
110xxxxxxx
(10 bits total, 3 bit prefix + 7 bits data)
168 -
679
1110xxxxxxxx
(13 bits total, 4 bit prefix + 9 bits data) etc.
If it was
desired to limit the system to 679, (or perhaps limit it
to
a slightly lower number and use the last few as an escape code for the
rare
occasion of encoding anything higher) then the last line would be as it
is
in the paper:
168 - 679
111xxxxxxxx
(12 bits total, 3 bit prefix + 9 bits data)
This gives excellent coding efficiency for larger
numbers, but at
the
expense of smaller values. In lossless coding, our scheme will
very
often be encoding 0, so the above system does not look promising.
An
alternative would be {2, 2, N} Start-Step-Stop:
0
- 3
0xx
( 3 bits total, 1 bit prefix + 2 bits data)
4
- 11
10xxxx
( 6 bits total, 2 bit prefix + 4 bits data)
12
- 83
110xxxxxx
( 9 bits total, 3 bit prefix + 6 bits data) (Thanks
Melchior!)
84 -
339
1110xxxxxxxx
(12 bits total, 4 bit prefix + 8 bits data) etc.
Or {1, 2,
N} Start-Step-Stop has another curve, favouring lower
values
still:
0 -
1
0x
( 2 bits total, 1 bit prefix + 1 bits data)
2
- 9
10xxx
( 5 bits total, 2 bit prefix + 3 bits data)
10
- 41
110xxxxx
( 8 bits total, 3 bit prefix + 5 bits data)
42 -
169
1110xxxxxxx
(11 bits total, 4 bit prefix + 7 bits data) etc.
Peter
Fenwick describes new codes in which 0's are interspersed
after
1's to indicate that the (reversed) number is not finished yet.
These
"punctured" codes take a bit of getting used to, but are very efficient
at
higher values. The bit length at higher values approximates "1.5
log
N bits, in comparison to 2 log N bits for the Elias codes" (logs base
2).
There is a ragged pattern of code-word lengths.
Number
P1 P2
Dec Binary
0
00000
0 01
1
00001
101 001
2
00010
1001 1011
3
00011
11011 0001
4
00100
10001 10101
5
00101
110101 10011
6
00110
110011 110111
7
00111
1110111 00001
8
01000
1000001 101001
9
01001
1101001 100101
10
01010
1100101 1101101
11
01011
11101101 100011
12
01100
1100011 1101011
13
01101
11101011 1100111
14
01110
11100111 11101111
15
01111
111101111 000001
16
10000
1000001 1010001
The capacity of these various codes to help with coding
the
"stragglers"
in a lossless audio compression algorithm depends on many factors I
can't
be sure of at present. Those codes which take more than one bit
to
code 0 are clearly at a disadvantage, since with the border set
optimally
for Rice or "Pod"/Biased Elias Gamma, most (2/3 or more) of the numbers
will
be 0.
However, since these codes are highly efficient at coding
larger
integers,
the "cost" of having longer stragglers is much less. Standard
Rice
coding of stragglers of values more than about 3 bits long can clearly
be
improved upon with Biased Elias Gamma. This uses about 2 bits per bit
of
straggler to be coded. But Peter Fenwick's "punctured" codes use
only
about 1.5 bits for longer values. This should enable the
"boundary"
separating the stragglers from the bits to be sent without compression
further
to the right, so reducing the number of bits to be sent uncompressed.
Some other links to sites
concerning
coding techniques
for variable length integers:
Tabulation details
These are low level details of how I processed the file
size
results. I used a batch file or GUI to compress all the WAV files
to
individual
compressed files with a distinctive file name extension. Then I
would
use a batch file containing "dir > dir.txt" to list the directory
and so
the file sizes. I would edit out all other lines except those of
the
compressed files and put them in the correct order, and then add those
to
sizes9.txt. Then I would use the MS-DOS command "type sizes9.txt"
to
show the text in an MS-DOS window. There is a rectangular text
select
command there and I selected the block of file sizes, complete with
commas
and by pressing Enter copied them to the clipboard. In thespreadsheet, I selected the column containing
file
sizes and pressed Control V. Voila! The spreadsheet does
the rest.
Then I manually copied the percentages and ratio from the spreadsheet
into
the HTML table.
The excel spreadsheet and "sizes9.txt" URL is
listed near the top
of
this page. To add your own pair of columns to the spreadsheet,
select
the block for an existing program, copy it to the clipboard, place your
cursor
in the Row 1 cell immediately to the right, and then paste into there.
This page was created with Netscape Communicator 4.7's
Composer.
In December 2000, Mozilla's
Composer
still has a way to go.
Updates in reverse order
2005 October 21. Added material at front
explaining why I
am no longer updating this page, with a few final updates, and a link
to the relevant Wikpedia page. Also did a few link updates and
fixes for problems reported to me. Thanks!
2003
January 12. Added link to WinAce and to Michael
P. McLaughlin's compendium of probability distributions. 2002
August 7. Added link to OptimFROG. 2002 July 17.
Added notes on demise of WaveZip web site. 2002 April
13. Updated licensing notes for Monkey's Audio
and
noted there is a Windows Media Player plugin. 2001
October 31. Added mention of new MUSICompress web site. 2001
March 22. Added mention of APT-X Windows DLL. 2001
January 17. Added mention of LPAC 3.0. 2000 December
19. Added listing of FLAC, but not tests. 2000 December
18. Slight change do DAXK notes - that the
Mac version
performs better than the PC version. 2000 December 14. Added
mention of MKT and updated RKAU results,
with
extra tables showing which of the options worked best for each file.
Added
a table in the RKAU section on the options available in all programs
for
using stereo correlations. Rounded average file size and
compression
ratios to the nearest number, up or down, so 67.545 becomes 67.55
and
67.544 becomes 67.54. 2000 December 12. Completely revised
section on Rice coding etc.
adding
material on Elias Gamma codes. Added mention of the DAKX Windows
version
1.0. 2000 December 11. Added test results for RKAU
1.07.
Mentioned
RAR. 2000 December 10. Page completely revised. The old page
is here.
Robin Whittle rw@firstpr.com.au
Return to the main page of the First Principles
web
site.
�
{kind=link}
{kind=link}
{kind=link}